大数据稳定性方案设计
前期技术调研结论
- emr默认支持cos,只需修改hdfs路径指向
- Spark、nifi、spark streaming、sqoop等组件可无缝访问cos数据
- Spark streaming写cos性能基本和本地盘保持一致
- 业务代码直接写压缩parquet和写csv性能低23%(大小及写入时间固定)
- DLC可直接支持parquet或json等格式、同时对现有复杂SQL基本100%支持
- Spark streaming读cos性能腾讯云默认有20%差异 (内部测试按现有参数count sql相差33%左右)
方案
现状
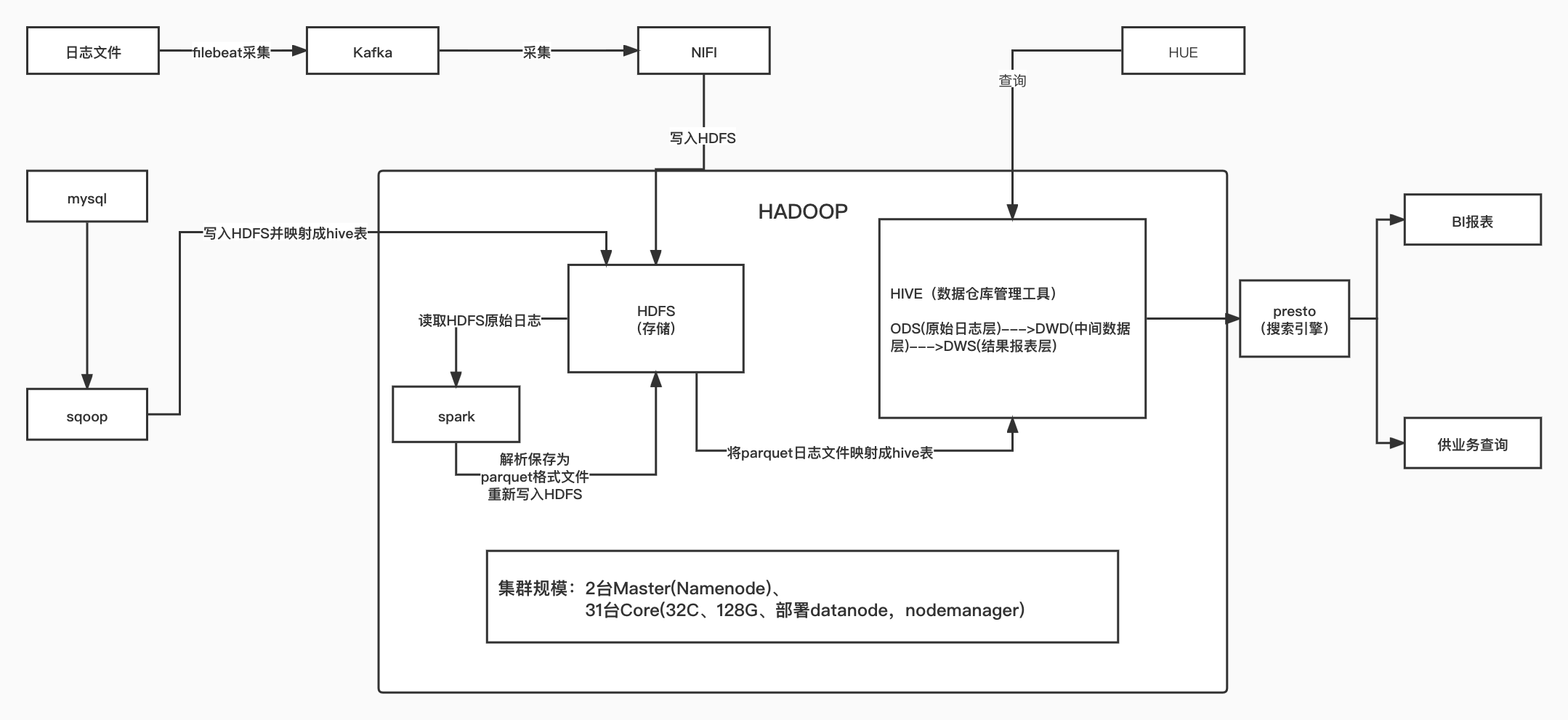
数据流转详情:
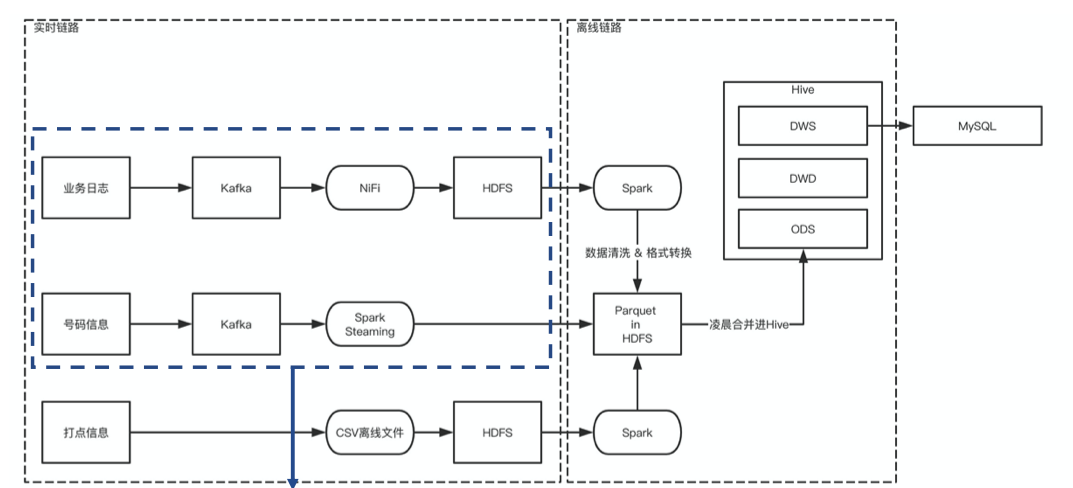
方案1
优点
- 业务代码无需改动
- 云厂商服务能满足80~90%以上需求
- cls作为关键链路,能备份原始日志、对数据进行加工、转换成parquet写入cos
缺点
-
对腾讯云组件依赖,对跨云迁移可能存在问题(阿里云有类似能力)
-
转换parquet需要4月低上线
方案2
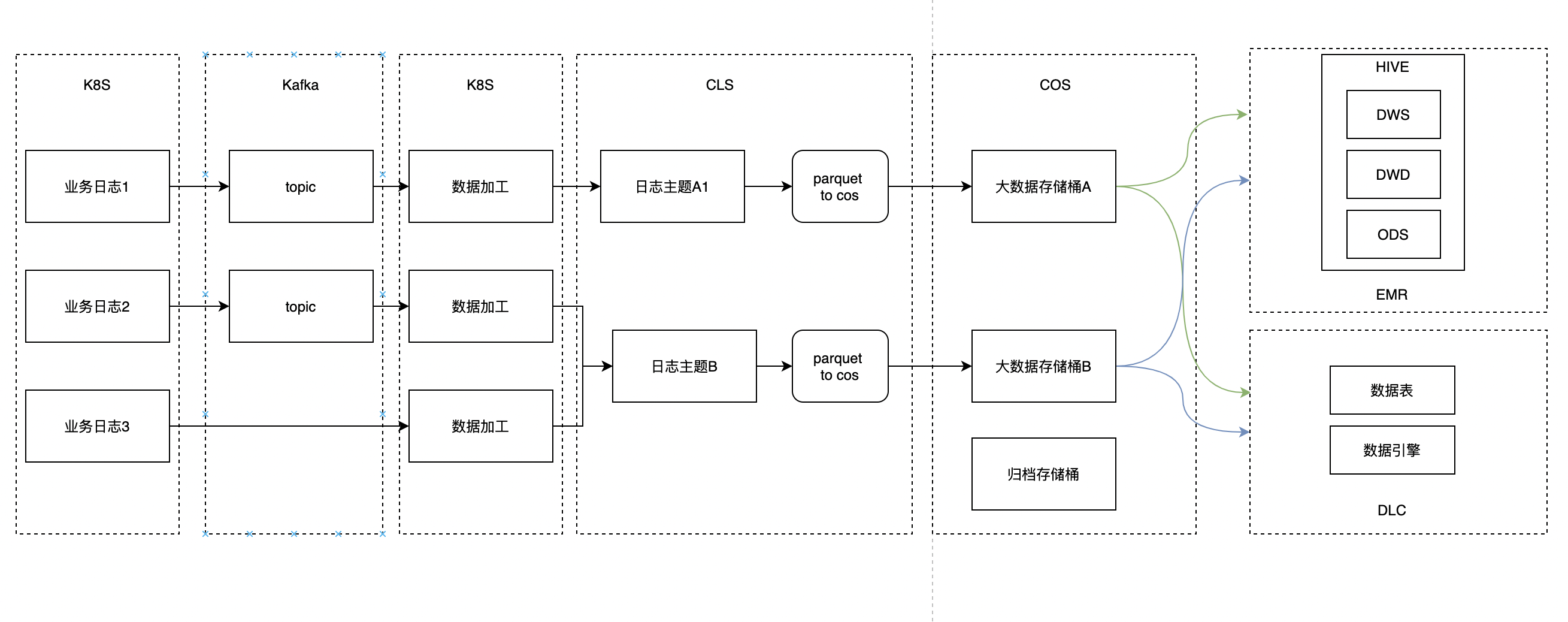
优点
- 简化数据采集流程(业务方可直接在业务代码或者消费kafka方式对数据进行做ETL处理)
- 大数据不用关心数据ETL
缺点
- 需要业务做ETL处理
- 对腾讯云组件依赖,对跨云迁移可能存在问题
- 原始日志备份需要业务采用CLS方案或者自身工具
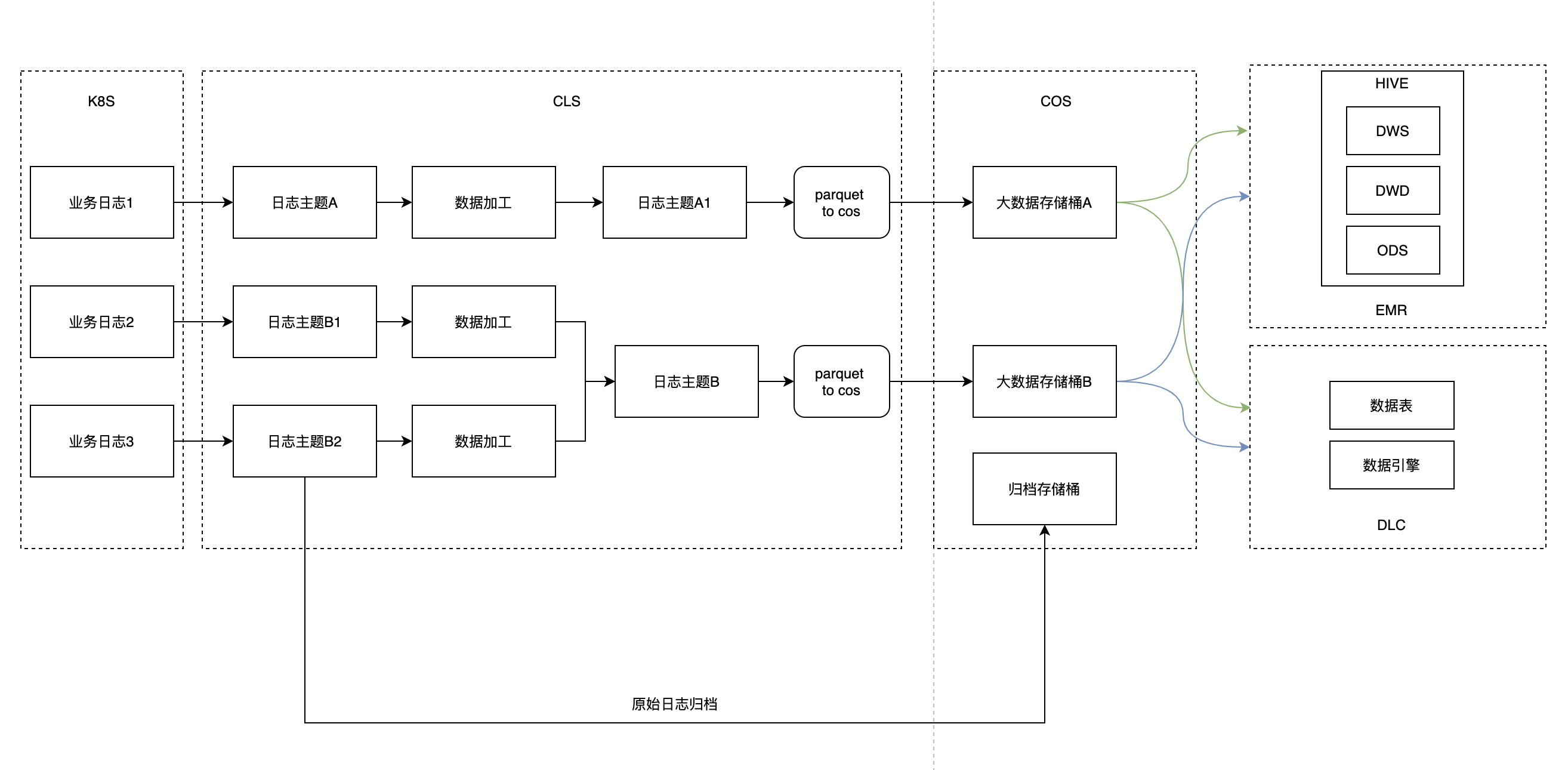
方案3
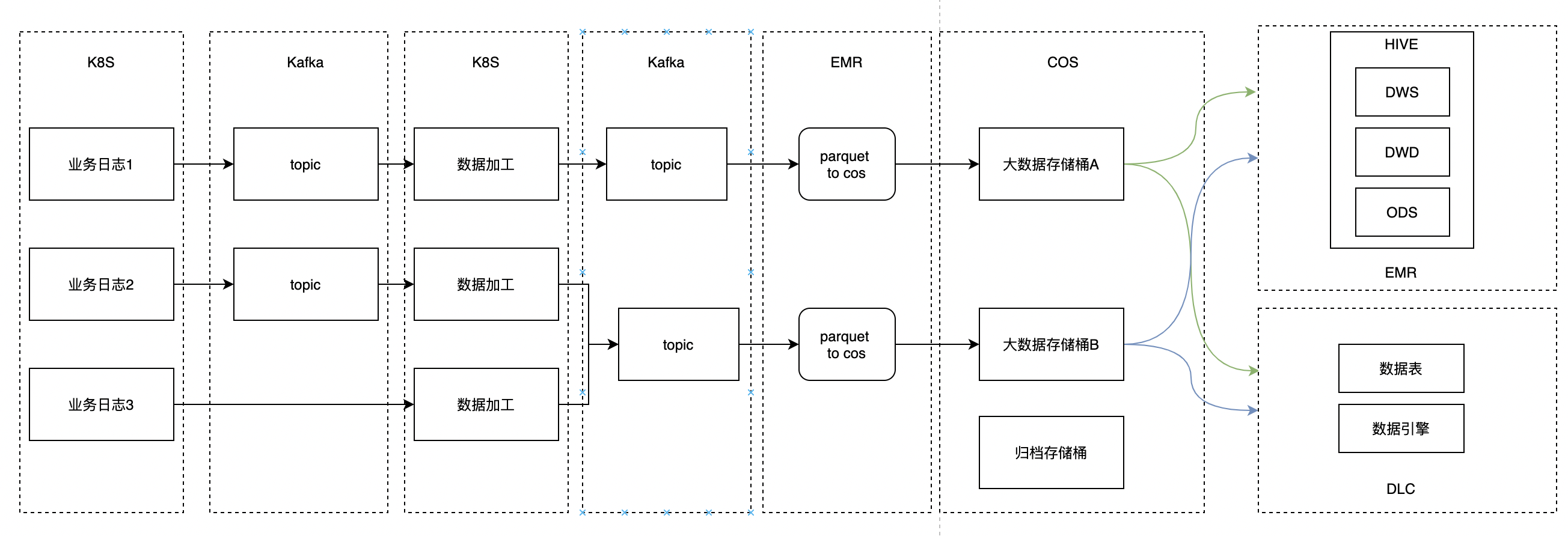
对比方案2,数据转parquet由大数据来处理
优点
-
不依赖云厂商能力
-
大数据只需要把数据转换成parquet落到cos
-
spark streaming转parquet写cos,性能测试和写本地盘基本保持一致
缺点
- parquet需要由emr来处理,占有emr资源
方案4
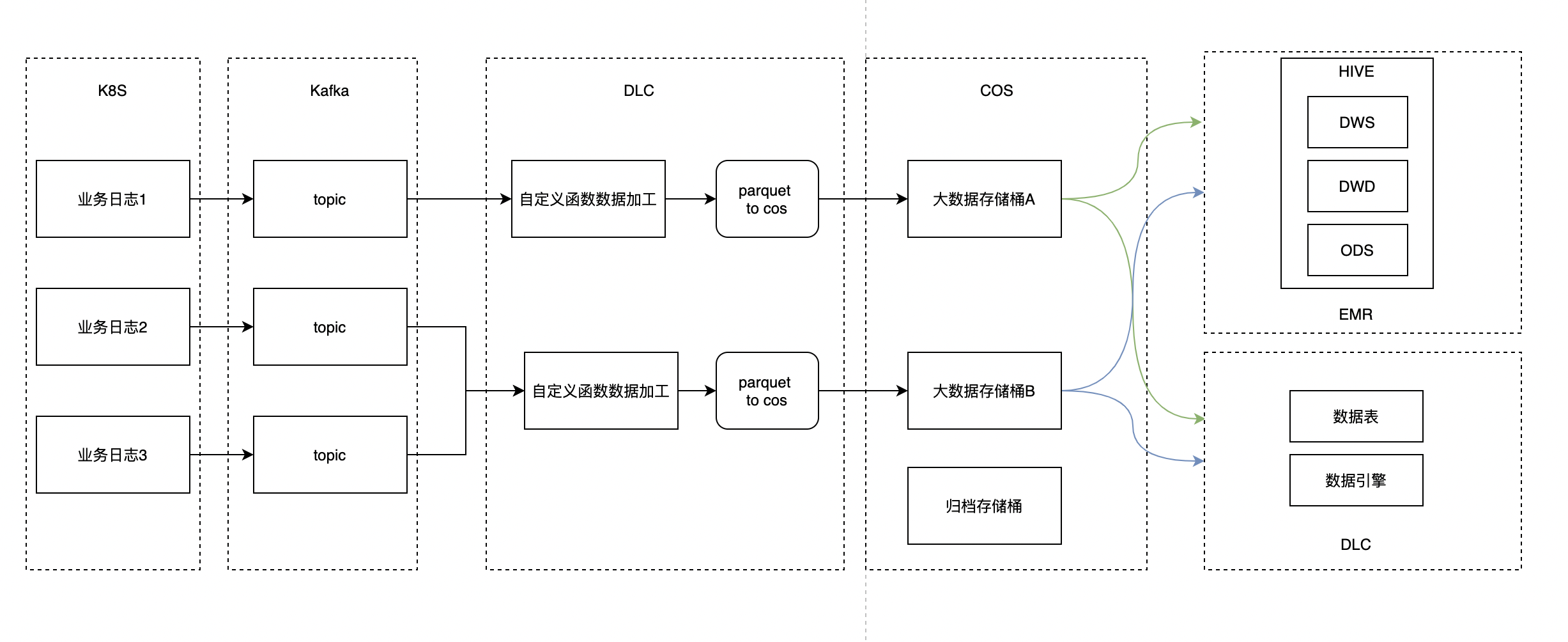
优点
- 大数据处理逻辑保持不变
- 数据ETL所依赖资源交给DLC处理
缺点
- 大数据维护组件增多
- DLC数据加工上线时间未定
结论
- 方案1整体链路简单、更适合大数据改造
- 数据ETL方案1不能match可采用方案2
目标
- 改造u3/dot/num/jump系统
- parquet前尽量交给云组件或者业务
- 大数据处理好数仓建设及稳定性
现状
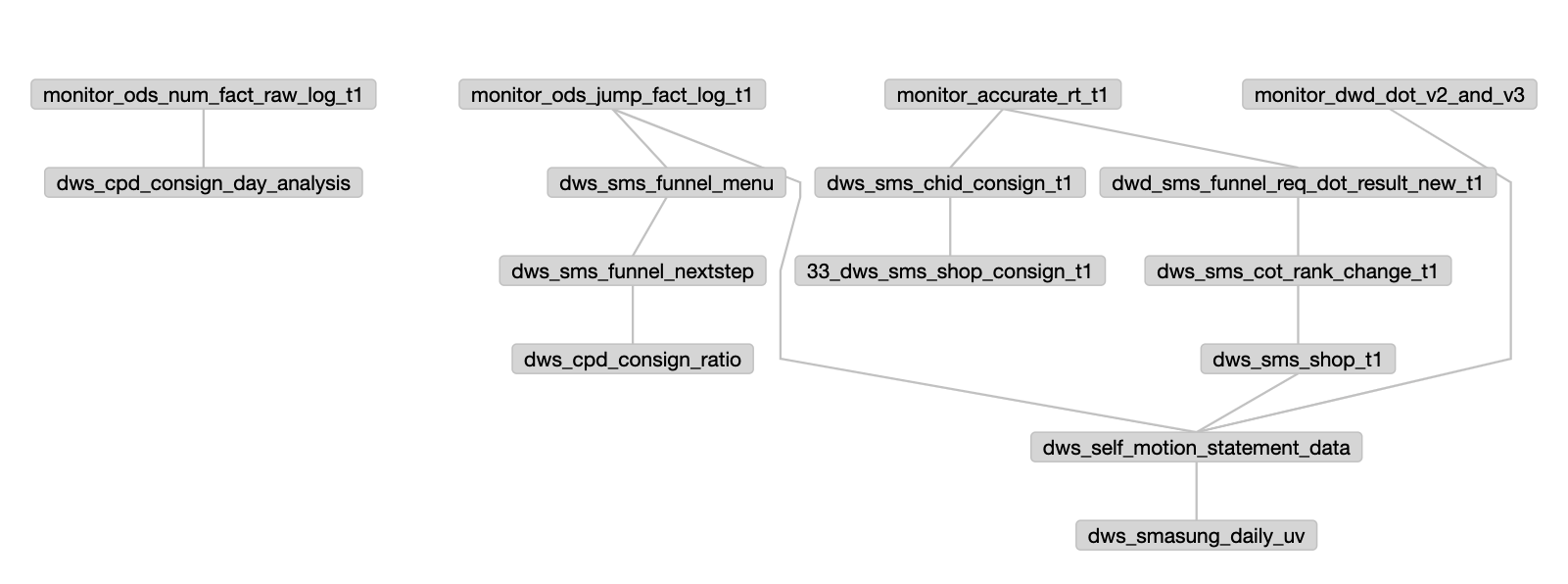
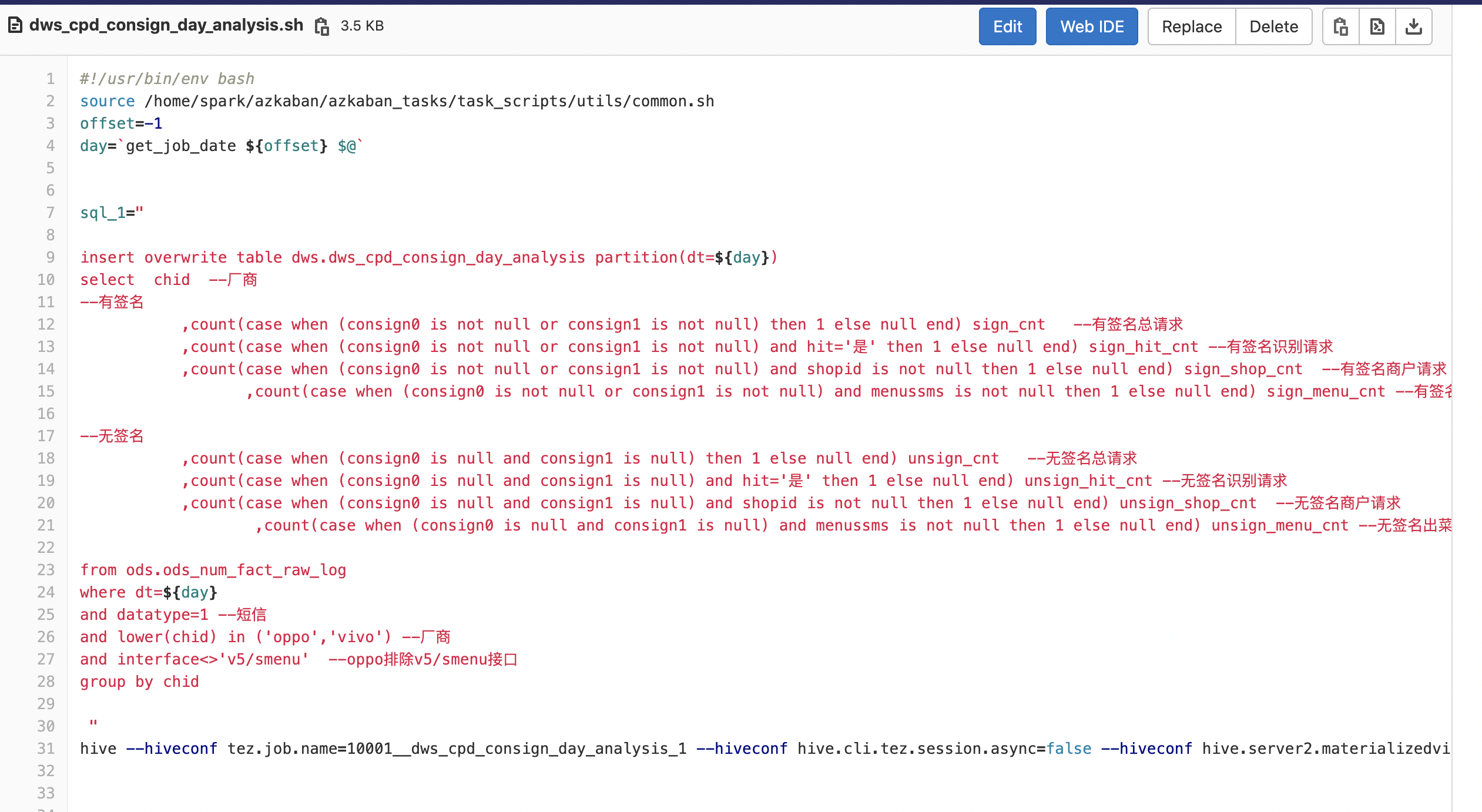
数据及相关任务
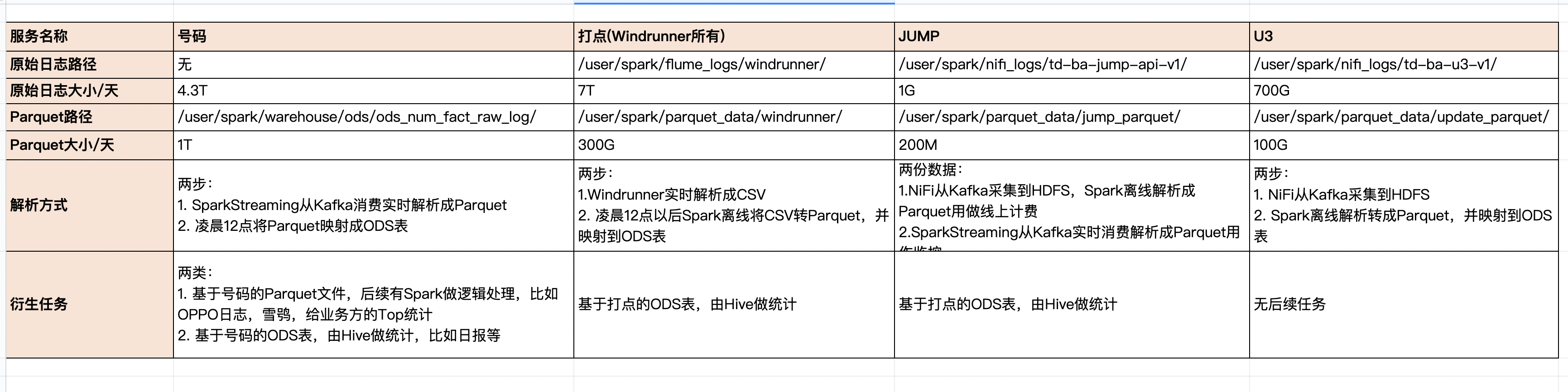
Azkaban
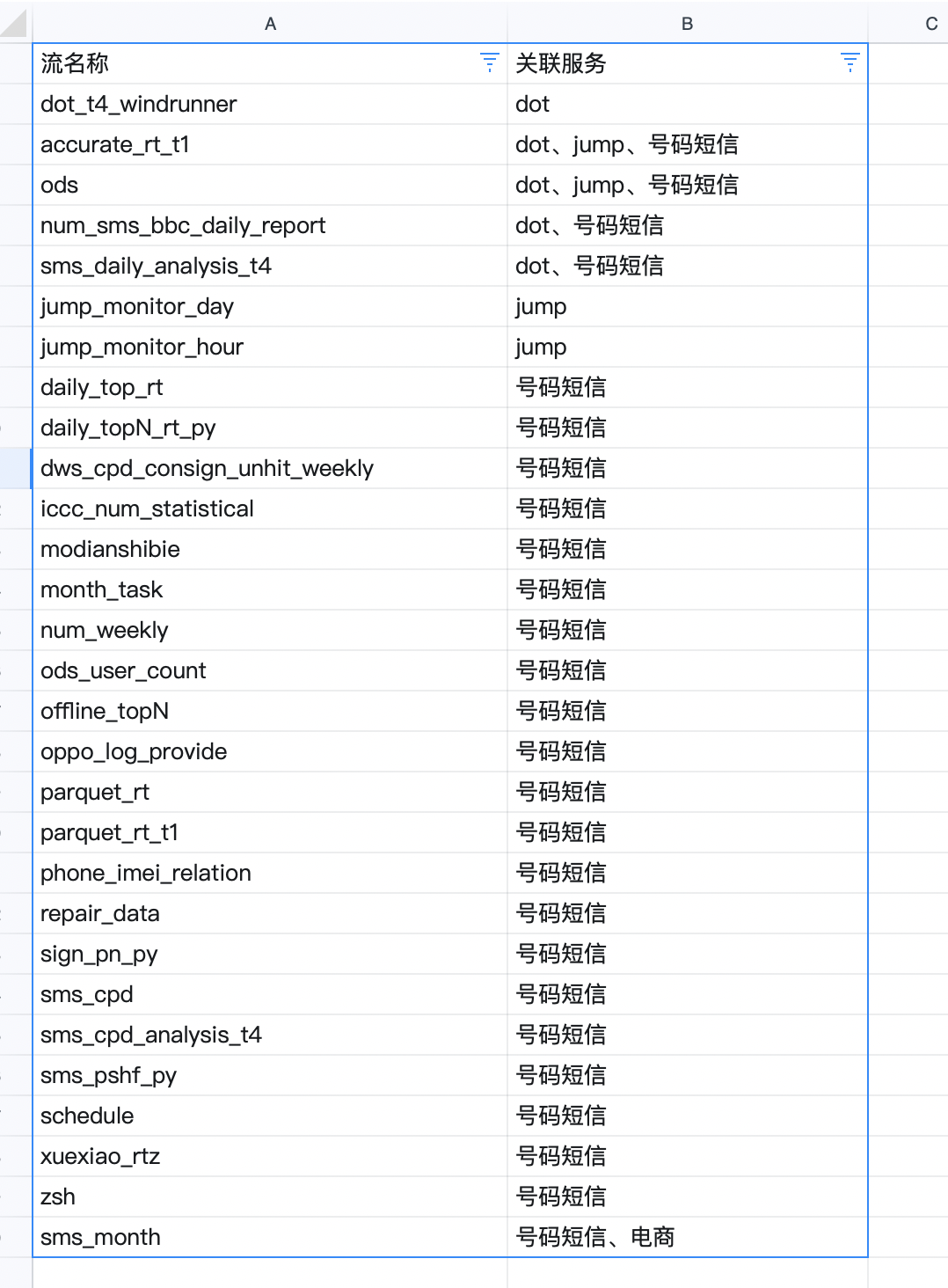
大数据稳定性
任务用例
Milestone
- 号码
- cos桶设计
- num-ods
- num-dwd
- Num-dws
- 数据ETL
- 写parquet
- 数仓建设
- partition划分
- 相关生产DWS、DWD任务存在一个流中
- 任务监控
- 任务性能优化
- oppo log改造
- cos桶设计
- dot
- cos桶设计
- 写parquet
- 数仓建设
- 任务监控
- 任务性能优化
- u3
- cos桶设计
- 停掉或者原始json替代?
- jump
- 写parquet
- 数仓建设
- 任务监控
- 任务性能优化