IO多路复用
在讲解IO多路复用前,我们需要先从IO开始。简单了解下IO基本原理,也能方便我们后续理解IO多路复用的复杂原理
什么是IO
**在计算机操作系统中,所谓I/O就是输入(Input)和输出(Output)缩写。通常指数据在计算机设备之间的输入和输入、外部世界与计算机之间的通信。**例如,键盘或鼠标是电脑的输入设备,而监控器和打印机是输出设备。电脑之间的通信设备(如电信调制解调器和网卡)通常执行输入和输出操作。
什么是文件IO
操作系统中,运行一个程序其实就是一个文件I/O。其中程序的载入、文件的打开,这些操作都与I/O密不可分。
文件I/O是指对文件的输入/输出操作,也就是对文件读写。Linux下一切皆为文件,其所有的I/O操作都是通过读写文件来完成的。
一个通用的IO模型通常包括打开文件、读写文件、关闭文件这些基本操作,主要涉及到4个函数:open()、read()、write()以及close()。
什么是网络IO
我们日常生活中,发送一条微信聊天给好友从本质上就是网络I/O。消息是需要从我本地客户端通过网络发送给服务器,然后由服务器转发消息给好友客户端。好友与自己微信客户端需要和微信服务端保存TCP长连接。而要想客户端和服务器能在网络中通讯,必须使用socket编程,其中网络I/O主要是通过socket套接字的读写。
接下来,我们看看socket通讯流程来了解网络I/O机制
ServerSocket
首选,我们先通过一段代码看服务器socket创建过程。
public class MyServer {
public static void main(String[] args){
try{
ServerSocket ss = new ServerSocket(6666);
Socket s = ss.accept();//establishes connection
DataInputStream dis=new DataInputStream(s.getInputStream());
String str=(String)dis.readUTF();
System.out.println("message= "+str);
ss.close();
}catch(Exception e){System.out.println(e);}
}
}
}
public class ServerSocket {
...
public ServerSocket(int port, int backlog, InetAddress bindAddr) throws IOException {
setImpl();
if (port < 0 || port > 0xFFFF)
throw new IllegalArgumentException(
"Port value out of range: " + port);
if (backlog < 1)
backlog = 50;
try {
bind(new InetSocketAddress(bindAddr, port), backlog);
} catch(SecurityException e) {
close();
throw e;
} catch(IOException e) {
close();
throw e;
}
}
public void bind(SocketAddress endpoint, int backlog) throws IOException {
if (isClosed())
throw new SocketException("Socket is closed");
if (!oldImpl && isBound())
throw new SocketException("Already bound");
if (endpoint == null)
endpoint = new InetSocketAddress(0);
if (!(endpoint instanceof InetSocketAddress))
throw new IllegalArgumentException("Unsupported address type");
InetSocketAddress epoint = (InetSocketAddress) endpoint;
if (epoint.isUnresolved())
throw new SocketException("Unresolved address");
if (backlog < 1)
backlog = 50;
try {
SecurityManager security = System.getSecurityManager();
if (security != null)
security.checkListen(epoint.getPort());
getImpl().bind(epoint.getAddress(), epoint.getPort());
// 监听
getImpl().listen(backlog);
bound = true;
} catch(SecurityException e) {
bound = false;
throw e;
} catch(IOException e) {
bound = false;
throw e;
}
}
...
}
-
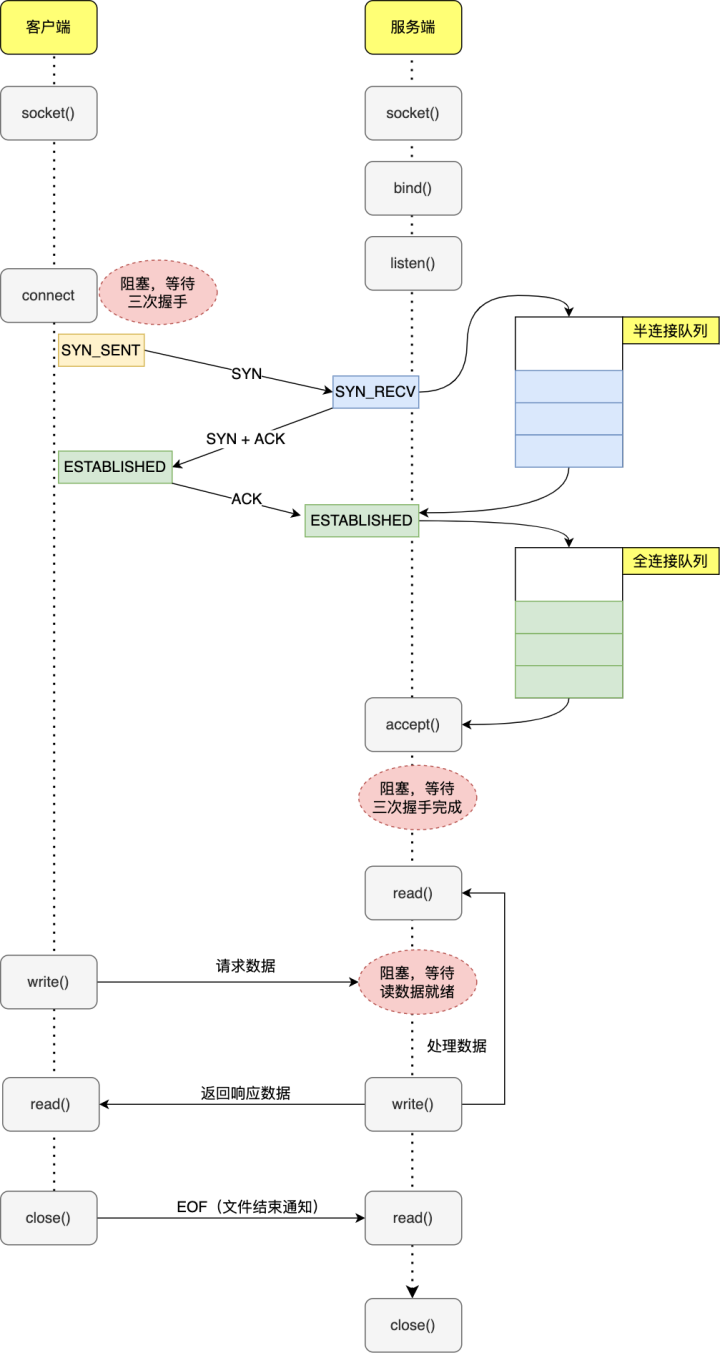
服务器首先调用
socket()函数,创建一个传输协议为TCP的Socket,接着调用bind()函数,给这个socket绑定一个IP地址和端口- **绑定端口目的:**当内核收到TCP报文,通过TCP端口号找到应用程序,然后发送数据给应用程序
- **绑定IP地址目的:**一台机器可能有多个网卡,每个网卡都有对应IP地址。内核收到网卡上数据包后,通过IP判断监听的应用程序
-
绑定完IP地址和端口后,调用
listen()函数进行监听对应端口号。listen()函数参数backlog代表允许客户端连接队列最大长度 -
服务器进入监听状态后,通过调用
accpet()函数,来从内核获取客户端连接。如果没有客户端连接,会一直阻塞等待客户端连接。
ClientSocket
连接完服务器创建socket过程,我们再来了解客户端是怎么发起连接的。
public class MyClient {
public static void main(String[] args) {
try{
Socket s=new Socket("localhost",6666);
DataOutputStream dout=new DataOutputStream(s.getOutputStream());
dout.writeUTF("Hello Server");
dout.flush();
dout.close();
s.close();
}catch(Exception e){System.out.println(e);}
}
}
}
public class Socket {
...
private Socket(SocketAddress address, SocketAddress localAddr,
boolean stream) throws IOException {
setImpl();
// backward compatibility
if (address == null)
throw new NullPointerException();
try {
createImpl(stream);
if (localAddr != null)
bind(localAddr);
// 连接
connect(address);
} catch (IOException | IllegalArgumentException | SecurityException e) {
try {
close();
} catch (IOException ce) {
e.addSuppressed(ce);
}
throw e;
}
}
...
}
-
客户端创建socket,调用
connect()函数发起连接,然后进行TCP三次握手建立连接。 -
第一次握手完成,服务器端会创建socket(这个socket是连接socket),将其放入半连接队列中。第三次握手完成,系统会把 socket 从半连接队列移出放入全连接队列中。
-
当建立连接后,服务端的
accpet()函数,就会从内核TCP全连接队列中移出socket返回给应用程序,之后此 socket 就可以与客户端 socket 正常通信了。默认情况下如果全连接队列里没有 socket,则 accept 会阻塞等待三次握手完成 -
连接建立后,客户端和服务端就开始相互传输数据了,双方都可以通过
read()和write()函数来读写数据。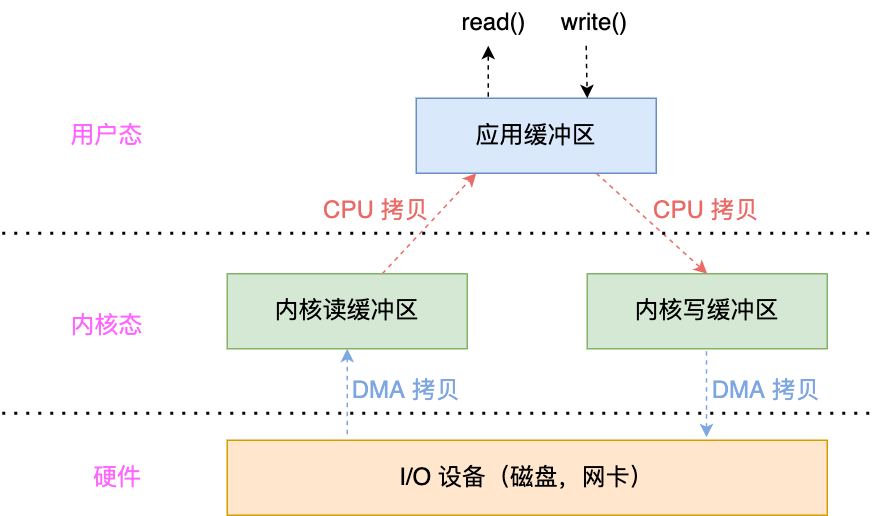
阻塞 I/O(blocking IO)
前面介绍socket相关代码,其实就是一个阻塞 I/O(blocking IO)。
- 服务端进程发起IO系统调用后,进程被阻塞,转到内核空间去等待数据
- 当服务器正在读取某一客户端发送的数据时,其他客户端需要同步等待
多进程IO模型
针对传统阻塞I/O模型一个服务器同一时间只能服务一个客户端请求,如果想要服务器支持多个客户端,其中比较常见的方式是是用多进程模型,也就是为每个客户端分配一个进程来处理。
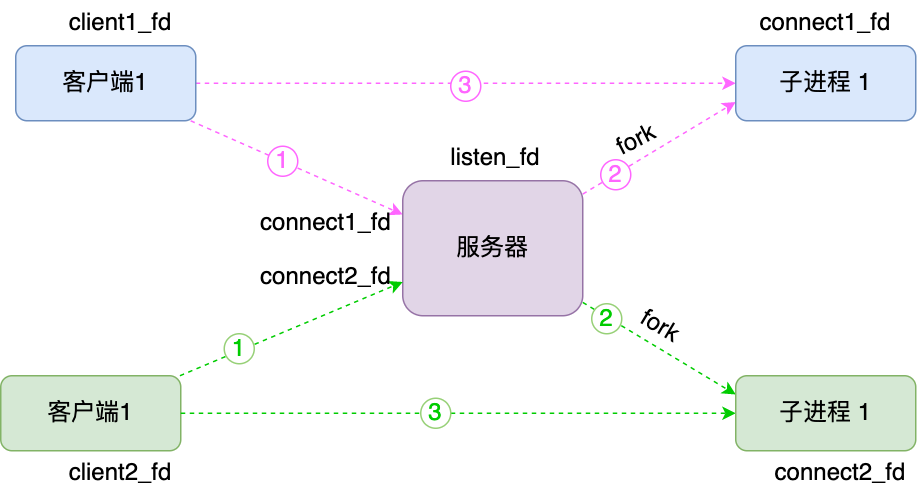
- 服务器主进程负责监听客户端连接,一旦与客户端连接完成,
accept()函数返回已连接socket,这时通过fork()函数创建一个子进程,fork()函数把父进程所有数据(文件描述符、内存地址空间、程序计数器、执行代码等)复制一份. - 子进程处理已连接socket的读写处理,即使出现阻塞也不影响父进程
- 父进程继续监听客户端连接,交由其他子进程处理
程序伪代码如下:
while(1) {
connfd = accept(listenfd); // 阻塞建立连接
// fork 创建一个新进程
if (fork() == 0) {
// accept 后子进程开始工作
doWork(connfd);
}
}
void doWork(connfd) {
int n = read(connfd, buf); // 阻塞读数据
doSomeThing(buf); // 利用读到的数据做些什么
close(connfd); // 关闭连接,循环等待下一个连接
}
通过fork出子进程方式,确实解决了单进程阻塞无法处理其他客户端请求的问题,但带来了新的问题:
- 内存地址空间、程序计数器等复制非常耗时
- 每个请求创建一个进程,而进程创建是需要有开销的
于是基于多进程IO模型,又衍生出多线程IO模型
多线程IO模型
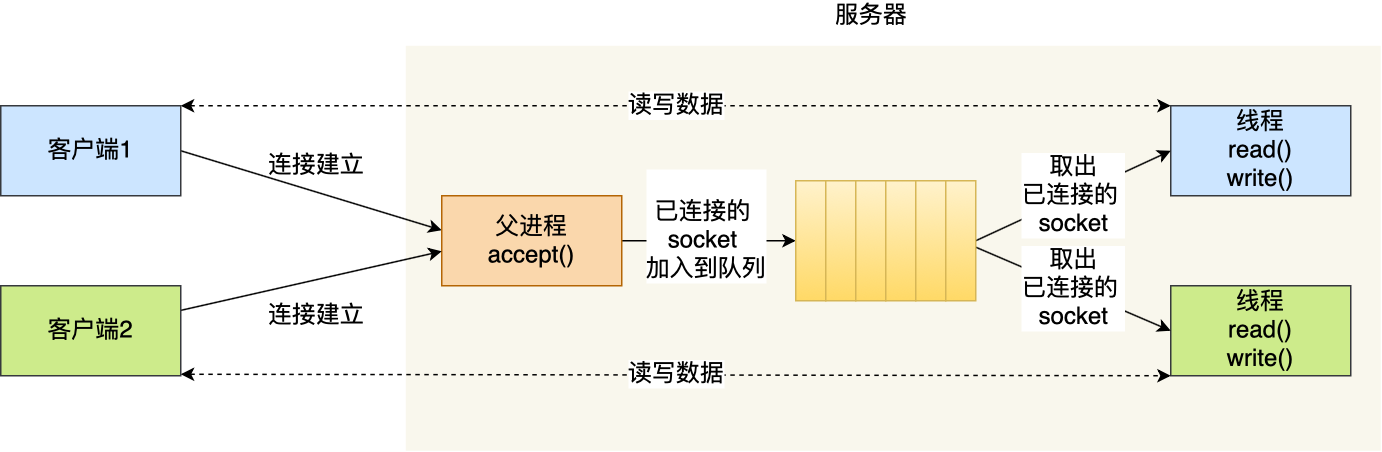
- 主线程监听客户端连接,当服务器与客户端完成TCP三次握手后,服务端创建handler线程同时把已连接socket交给handler处理
- handler线程处理已连接socket,处理与客户端读写
通知这种方式避免了创建进程开销,但线程创建也存在开销:
对操作系统来说每个线程创建需要给它分配内存(1M内存)、列入调度,同时线程过多会出现频繁CP U上下文切换以及内存换页等操作
IO多路复用
既然为每个请求分配一个进程/线程的方式不合适,那有没有可能只使用一个进程来维护多个 Socket 呢?答案是有的,那就是 I/O 多路复用技术。
IO多路复用是指用一个进程来监听listen socket(监听socket)的连接建立事件,connect socket(已连接socket)的读写事件,一旦数据就绪,内核就会唤醒用户进程去处理socket相应事件
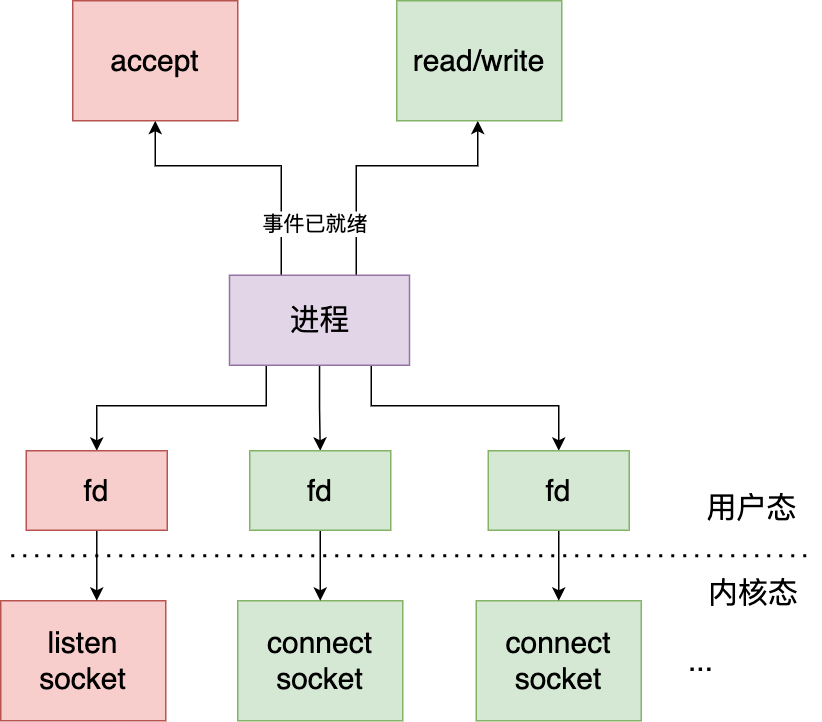
多路是指网络连接,复用是指同一个进程
本质上IO复用就是一个进程使用select/poll/epoll同时监控多个阻塞IO(文件描述符)。一旦发现一个或多个IO读就绪或者写就绪,它就通知进程准备读写操作。
也就是说select/poll/epoll能监听到socket数据就绪,然后通过用户进程去处理。
select
select实现多路复用方式
- 将已连接socket都放入一个文件描述符列表,然后调用
select()函数将文件描述符列表拷贝到内核中 - 内核通过遍历文件描述符列表,检查是否有网络事件产生
- 当检查到网络事件后,将此文件描述符标识为可读写
- 接着再把整个文件描述符列表拷贝回用户态
- 然后用户态再遍历查找可读写文件描述符,处理
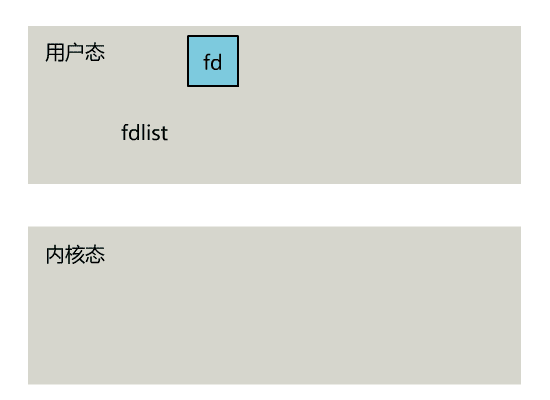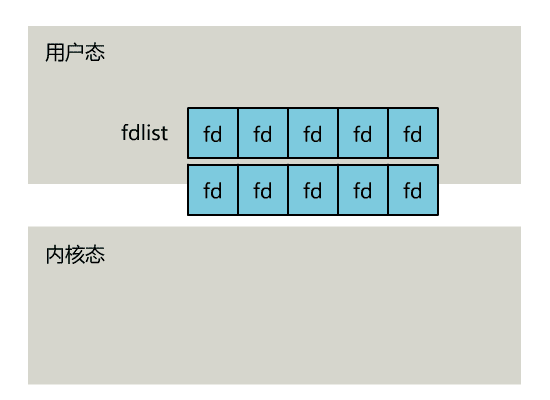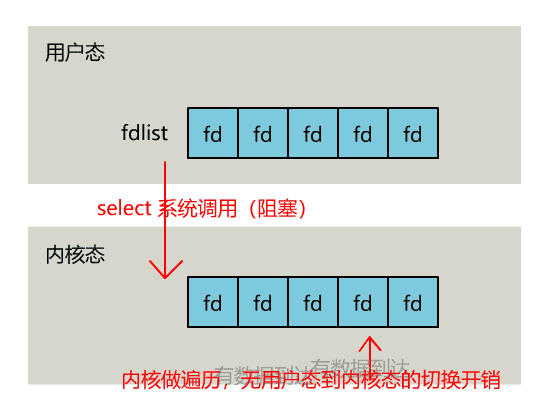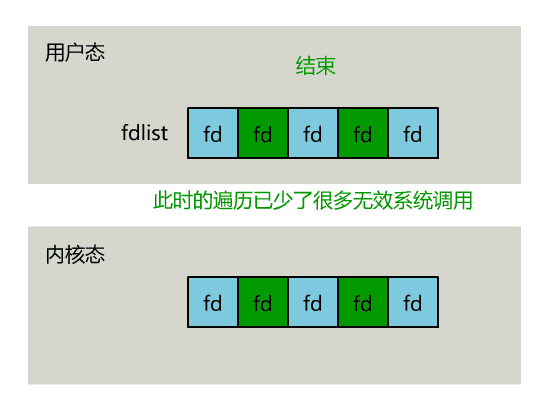
所以,对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ,而且还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
select伪代码如下:
int listen_fd,conn_fd; //监听套接字和已连接套接字的变量
listen_fd = socket() //创建套接字
bind(listen_fd) //绑定套接字
listen(listen_fd) //在套接字上进行监听,将套接字转为监听套接字
fd_set master_rset; //被监听的描述符集合,关注描述符上的读事件
int max_fd = listen_fd
//初始化 master_rset 数组,使用 FD_ZERO 宏设置每个元素为 0
FD_ZERO(&master_rset);
//使用 FD_SET 宏设置 master_rset 数组中位置为 listen_fd 的文件描述符为 1,表示需要监听该文件描述符
FD_SET(listen_fd,&master_rset);
fd_set working_set;
while(1) {
// 每次都要将 master_set copy 给 working_set,因为 select 返回后 working_set 会被内核修改
working_set = master_set
/**
* 调用 select 函数,检测 master_rset 数组保存的文件描述符是否已有读事件就绪,
* 返回就绪的文件描述符个数,我们只关心读事件,所以其它参数都设置为 null 了
*/
nready = select(max_fd+1, &working_set, NULL, NULL, NULL);
// 依次检查已连接套接字的文件描述符
for (i = 0; i < max_fd && nready > 0; i++) {
// 说明 fd = i 的事件已就绪
if (FD_ISSET(i, &working_set)) {
nready -= 1;
//调用 FD_ISSET 宏,在 working_set 数组中检测 listen_fd 对应的文件描述符是否就绪
if (FD_ISSET(listen_fd, &working_set)) {
//如果 listen_fd 已经就绪,表明已有客户端连接;调用 accept 函数建立连接
conn_fd = accept();
//设置 master_rset 数组中 conn_fd 对应位置的文件描述符为 1,表示需要监听该文件描述符
FD_SET(conn_fd, &master_rset);
if (conn_fd > max_fd) {
max_fd = conn_fd;
}
} else {
//有数据可读,进行读数据处理
read(i, xxx)
}
}
}
}
看起来 select 很好,但在生产上用处依然不多,主要是因为 select 有以下劣势:
- 每次调用 select,都需要把 fdset 从用户态拷贝到内核态,在高并发下是个巨大的性能开销(可优化为不拷贝)
- 调用 select 阻塞后,用户进程虽然没有轮询,但在内核还是通过遍历的方式来检查 fd 的就绪状态(可通过异步 IO 唤醒的方式)
- select 只返回已就绪 fd 的数量,用户线程还得再遍历所有的 fd 查看哪些 fd 已准备好了事件(可优化为直接返回给用户进程数据已就绪的 fd 列表)
正在由于 1,2 两个缺点,select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的,在 Linux 系统中,由内核中的 FD_SETSIZE 限制, 默认最大值为 1024,只能监听 0~1023 的文件描述符。
poll
poll 的机制其实和 select 一样,唯一比较大的区别其实是把 1024 这个限制给放开了,取而代之用动态数组,以链表形式来组织。
虽然通过放开限制可以使内核监听上万 socket,但由于和上面说的select两点劣势,它的性能依然不高,所以生产上也不怎么使用
epoll
首先我们看看epoll原理:
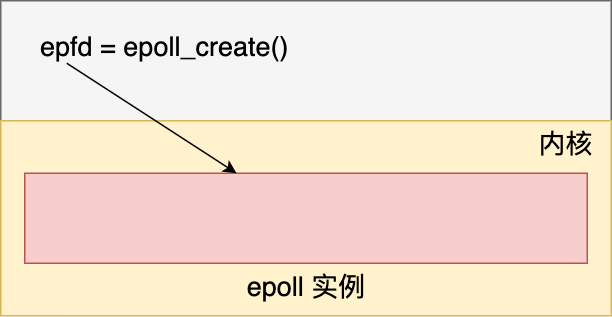
- 首先,epoll是内核的数据结构,这个数据结构允许进程监听多个socket事件。一般,我们通过epoll_create来创建这个实例。
-
其次,epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字符,把需要监控的 socket 通过
epoll_ctl()函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删查一般时间复杂度是O(logn),通过对这棵黑红树进行操作,这样就不需要像 select/poll 每次操作时都传入整个 socket 集合,只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。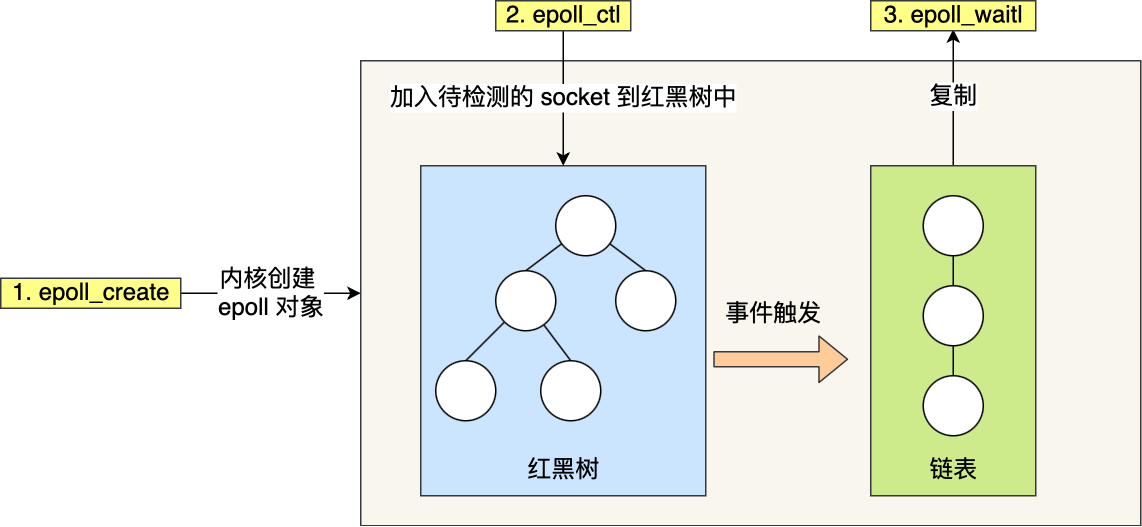
-
最后,再调用
epoll_wait()函数将控制权交给内核。epoll 使用事件驱动的机制,内核里维护了一个就绪链表来记录就绪事件。当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中。然后再唤醒用户进程,之后用户进程遍历此就绪列表。

epoll 的方式即使监听的 Socket 数量越多的时候,效率不会大幅度降低,能够同时监听的 Socket 的数目也非常的多了,上限就为系统定义的进程打开的最大文件描述符个数
epoll伪代码如下:
int sock_fd,conn_fd; //监听套接字和已连接套接字的变量
sock_fd = socket() //创建套接字
bind(sock_fd) //绑定套接字
listen(sock_fd) //在套接字上进行监听,将套接字转为监听套接字
epfd = epoll_create(); //创建epoll实例,
//创建epoll_event结构体数组,保存套接字对应文件描述符和监听事件类型
ep_events = (epoll_event*)malloc(sizeof(epoll_event) * EPOLL_SIZE);
//创建epoll_event变量
struct epoll_event ee
//监听读事件
ee.events = EPOLLIN;
//监听的文件描述符是刚创建的监听套接字
ee.data.fd = sock_fd;
//将监听套接字加入到监听列表中
epoll_ctl(epfd, EPOLL_CTL_ADD, sock_fd, &ee);
while (1) {
//等待返回已经就绪的描述符
n = epoll_wait(epfd, ep_events, EPOLL_SIZE, -1);
//遍历所有就绪的描述符
for (int i = 0; i < n; i++) {
//如果是监听套接字描述符就绪,表明有一个新客户端连接到来
if (ep_events[i].data.fd == sock_fd) {
conn_fd = accept(sock_fd); //调用accept()建立连接
ee.events = EPOLLIN;
ee.data.fd = conn_fd;
//添加对新创建的已连接套接字描述符的监听,监听后续在已连接套接字上的读事件
epoll_ctl(epfd, EPOLL_CTL_ADD, conn_fd, &ee);
} else { //如果是已连接套接字描述符就绪,则可以读数据
...//读取数据并处理
read(ep_events[i].data.fd, ..)
}
}
}
可以看到 epoll 很好地解决了 select 的痛点
- 「每次调用 select 都把 fd 集合拷贝给内核」优化为「只有第一次调用 epoll_ctl 添加感兴趣的 fd 到内核的 epoll 实例中,之后只要调用 epoll_wait 即可,数据集合不再需要拷贝」
- 「用户进程调用 select 阻塞后,内核会通过遍历的方式来同步检查 fd 的就绪状态」优化为「内核使用异步事件通知」
- 「select 仅返回已就绪 fd 的数量,用户线程还得再遍历一下所有的 fd 来挨个检查哪个 fd 的事件已就绪了」优化为「内核直接返回已就绪的 fd 集合」
内容小结
最基础的 TCP 的 Socket 编程,它是阻塞 I/O 模型,基本上只能一对一通信,那为了服务更多的客户端,我们需要改进网络 I/O 模型。
比较传统的方式是使用多进程/线程模型,每来一个客户端连接,就分配一个进程/线程,然后后续的读写都在对应的进程/线程,这种方式处理 100 个客户端没问题,但是当客户端增大到 10000 个时,10000 个进程/线程的调度、上下文切换以及它们占用的内存,都会成为瓶颈。
为了解决上面这个问题,就出现了 I/O 的多路复用,可以只在一个进程里处理多个文件的 I/O,Linux 下有三种提供 I/O 多路复用的 API,分别是: select、poll、epoll。
IO 多路复用主要有三个模型,select,poll,epoll,每一个都是对前者的改进:
- select 是每次调用时都要把 fd 集合拷贝给内核,而且内核是通过不断遍历这种同步的方式来检查 fd 是否有事件就绪,并且一旦检测到有事件后也只是返回有就绪事件的 fd 的个数,用户线程也需要遍历 fd 集合来查看 fd 是否已就绪,select 限制了 fd 的集合只能有 1024 个
- poll 和 select 的原理差不多,只不过是放开了 1024 个 fd 的限制,fd 的个数可以任意设置。但由于它的实现机制与 select 类似,所以也存在和 select 一样的性能瓶颈
- 为了彻底解决 select,poll 的性能瓶颈,epoll 出现了,它把需要监听的 fd 传给内核 epoll 实例,epoll 以红黑树的形式来管理这些 fd,这样每次 epoll 只需调用 epoll_wait 即可将控制权转给内核来监听 fd 的事件,避免了无意义的 fd 集合的拷贝,同时由于红黑树的高效,一旦某个 socket 来事件了,可以迅速从红黑树中查找到相应的 socket,然后再唤醒用户进程,此过程是异步的,比起 select 的同步唤醒又是一大进步,此时唤醒用户进程后,内核会把数据已就绪的 fd 放到一个就绪列表里传给用户进程,用户进程只需要遍历此就绪列表即可,比起 select 需要全部遍历也是一大进步,除此之外 epoll 引入了边缘触发让其在高并发下的表现也更加优异,正是由于 epoll 对 select,poll 的这些改进,也让它成为了 IO 多路复用绝对的王者