Kafka源码解读之KafkaController
前言
Kafka 集群中的节点能够同时承担两种角色,一个是作为 Broker 处理外部请求,另一个是作为 Controller 管理整个集群元数据。
Controller 在集群中负责的事件很多,比如:所有分区副本状态变化、集群状态变化、集群 meta 信息的一致性保证、Partition leader 的选举、broker 上下线等。
现在让我们思考一个问题,由于每个节点都会管理集群的元数据,那么各个节点数据是如果保持数据一致性的呢?
分布式共识算法有很多中,比如Paxos、Raft、Gossip、以及zookeeper ZAB。在Kafka v2.8之前选择zookeeper来作为共识服务,帮助kafka选举出一个“领导者”。这个“领导者”对应的kafkaController也被称为Leader,其他节点的KakfaController被称为Follower,在同一时刻,一个 Kafka 集群只能有一个 Leader 和 N 个 Follower。Leader向zookeeper上注册watcher协调相关事件,其他follower几乎不用监听zookeeper的状态变化。
接下来,让我们先通过了解Leader对zookeeper事件监听分类,逐步掌握kafkaController工作机制。
Kafka Zookeeper事件监听
熟悉zookeeper的人应该都比较清楚,zookeeper是基于事件监听模式,通过监控目录(zNode)的变化,来执行事件对应的回调函数。我们先总结下kafka Zookeeper事件监听,如下图:
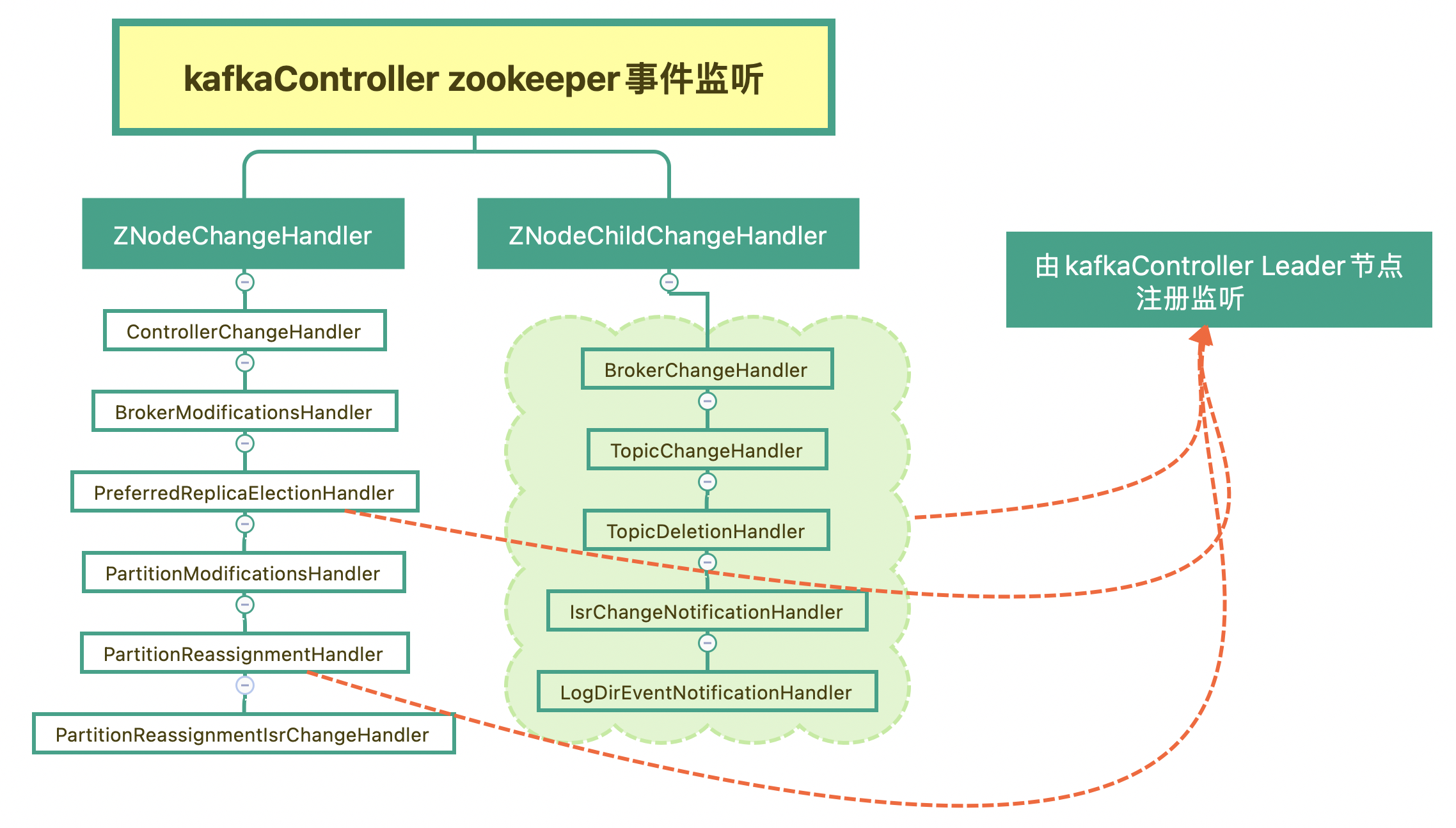
这些 ZooKeeper 监听器的作用:
- controllerChangeHandler:监听 /controller 节点变更的。这种变更包括节点创建、删除以及数据变更。
- brokerModificationsHandlers:监听 Broker 的数据变更,比如 Broker 的配置信息发生的变化。
- preferredReplicaElectionHandler:监听 Preferred Leader 选举任务。一旦发现新提交的任务,就为目标主题执行 Preferred Leader 选举。
- partitionModificationsHandlers:监控主题分区数据变更的监听器,比如,新增加了副本、分区更换了 Leader 副本。
- partitionReassignmentHandler:监听分区副本重分配任务。一旦发现新提交的任务,就为目标分区执行副本重分配。
- PartitionReassignmentIsrChangeHandler:
- brokerChangeHandler:监听 Broker 的数量变化。
- topicChangeHandler:监控主题数量变更。
- topicDeletionHandler:监听主题删除节点 /admin/delete_topics 的子节点数量变更。
- isrChangeNotificationHandler:监听 ISR 副本集合变更。一旦被触发,就需要获取 ISR 发生变更的分区列表,然后更新 Controller 端对应的 Leader 和 ISR 缓存元数据。
- logDirEventNotificationHandler:监听日志路径变更。一旦被触发,需要获取受影响的 Broker 列表,然后处理这些 Broker 上失效的日志路径。
其中有些监听器只有Controller才能注册的:
// KafkaController.scala
// 此函数被elect函数调用,只有当controller没有leader节点,且broker注册为leader节点才能调用此函数
private def onControllerFailover(): Unit = {
...
// before reading source of truth from zookeeper, register the listeners to get broker/topic callbacks
val childChangeHandlers = Seq(brokerChangeHandler, topicChangeHandler, topicDeletionHandler, logDirEventNotificationHandler,
isrChangeNotificationHandler)
childChangeHandlers.foreach(zkClient.registerZNodeChildChangeHandler)
val nodeChangeHandlers = Seq(preferredReplicaElectionHandler, partitionReassignmentHandler)
nodeChangeHandlers.foreach(zkClient.registerZNodeChangeHandlerAndCheckExistence)
...
}
这些监听器会注册到zk如下目录:
| 节点 | 监听类型 | 监听器 |
|---|---|---|
| /admin/reassign_partitions | 节点变更 | PartitionReassignmentHandler |
| /admin/preferred_replica_election | 节点变更 | PreferredReplicaElectionHandler |
| /admin/delete_topics | 子节点变更 | TopicDeletionHandler |
| /brokers/topics/[topic] | 节点变更 | TopicChangeHandler |
| /brokers/ids/[brokerid] | 子节点变更 | BrokerChangeHandler |
| /log_dir_event_notification | 子节点变更 | LogDirEventNotificationHandler |
| /isr_change_notification | 子节点变更 | IsrChangeNotificationHandler |
其他比如controllerChangeHandler监听器时在启动或者重新选举controller时被所有Broker注册。brokerModificationsHandlers和partitionModificationsHandlers监听节点信息和分区信息的改变然后更新本地元数据。
了解了这些监听器作用,接下来我们通过对源码学习逐步掌握kafkaController机制。
Controller启动
Kafka 的每台 Broker 在启动过程中,都会启动 Controller 服务,初始化的入口依然在KafkaServer的startup函数中,相关代码如下:
override def startup(): Unit = {
try {
info("starting")
...
/* start kafka controller */
kafkaController = new KafkaController(config, zkClient, time, metrics, brokerInfo, brokerEpoch, tokenManager, brokerFeatures, featureCache, threadNamePrefix)
kafkaController.startup()
...
}
}
接着KafkaController调用startup函数向zookeeper注册,并向事件管理器中添加一个启动事件
def startup() = {
// 第1步:注册ZooKeeper状态变更监听器,它是用于监听Zookeeper会话过期的
zkClient.registerStateChangeHandler(new StateChangeHandler {
override val name: String = StateChangeHandlers.ControllerHandler
override def afterInitializingSession(): Unit = {
eventManager.put(RegisterBrokerAndReelect)
}
override def beforeInitializingSession(): Unit = {
val queuedEvent = eventManager.clearAndPut(Expire)
// Block initialization of the new session until the expiration event is being handled,
// which ensures that all pending events have been processed before creating the new session
queuedEvent.awaitProcessing()
}
})
// 第2步:写入Startup事件到事件管理器
eventManager.put(Startup)
// 第3步:启动ControllerEventThread线程,开始处理事件队列中的ControllerEvent
eventManager.start()
}
事件管理器启动后,内部交由ControllerEventThread调度。首先,从事件队列中取出事件,由于队列调用时take()函数时阻塞的,直到队列中有事件才执行后续逻辑
override def doWork(): Unit = {
// 从事件队列中获取待处理的Controller事件,否则等待
val dequeued = pollFromEventQueue()
dequeued.event match {
// 如果是关闭线程事件,什么都不用做。关闭线程由外部来执行
case ShutdownEventThread => // The shutting down of the thread has been initiated at this point. Ignore this event.
case controllerEvent =>
_state = controllerEvent.state
// 更新对应事件在队列中保存的时间
eventQueueTimeHist.update(time.milliseconds() - dequeued.enqueueTimeMs)
try {
// 定义一个事件处理函数,调用ControllerEventProcessor类的process()函数执行逻辑
def process(): Unit = dequeued.process(processor)
// 处理事件,同时计算处理速
rateAndTimeMetrics.get(state) match {
case Some(timer) => timer.time { process() } // 延迟调度
case None => process()
}
} catch {
case e: Throwable => error(s"Uncaught error processing event $controllerEvent", e)
}
_state = ControllerState.Idle
}
}
由于前面在启动时,放入了一个Startup事件到队列中,所以最终会调用KafkaController类的process()函数
// KafkaController的process方法,
override def process(event: ControllerEvent): Unit = {
try {
event match {
......
case Startup =>
processStartup() // 处理Startup事件
}
}
......
}
private def processStartup(): Unit = {
// 注册ControllerChangeHandler ZooKeeper监听器
zkClient.registerZNodeChangeHandlerAndCheckExistence(controllerChangeHandler)
// 在 controller 不存在的情况下选举 controller,存在的话,就是从 zk 获取当前的 controller 节点信息
elect()
}
从这段代码可知,process 方法调用 processStartup 方法去处理 Startup 事件。而 processStartup 方法又会调用 zkClient 的 registerZNodeChangeHandlerAndCheckExistence 方法注册 ControllerChangeHandler 监听器。同时会调用elect()方法选举KafkaController的Leader节点。
Controller选举
只有出现如下3个场景才会选举kafkaController Leader:
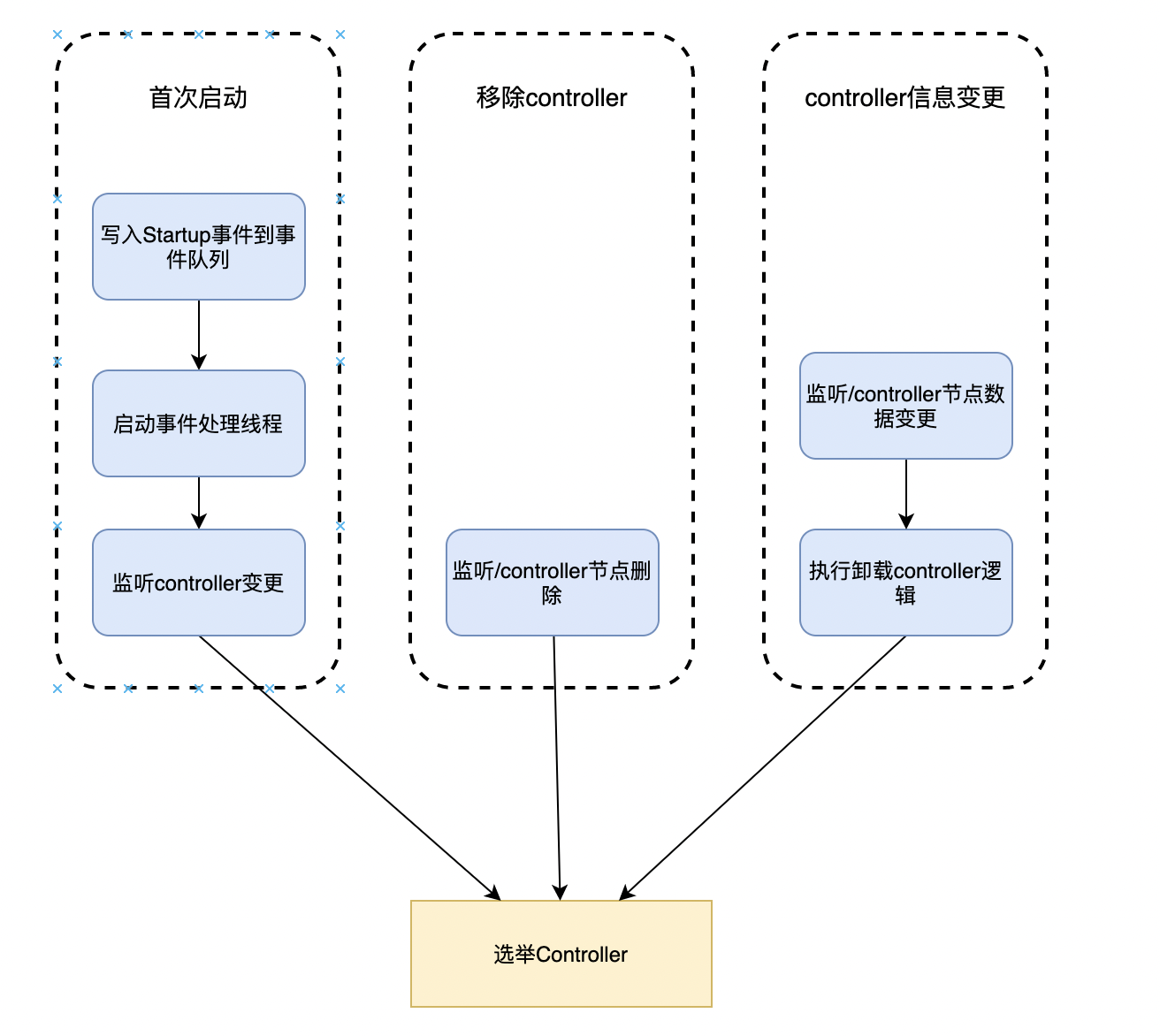
现在假设我们存在3个Broker节点,所有节点初次启动,节点启动不分先后顺序
首次启动
-
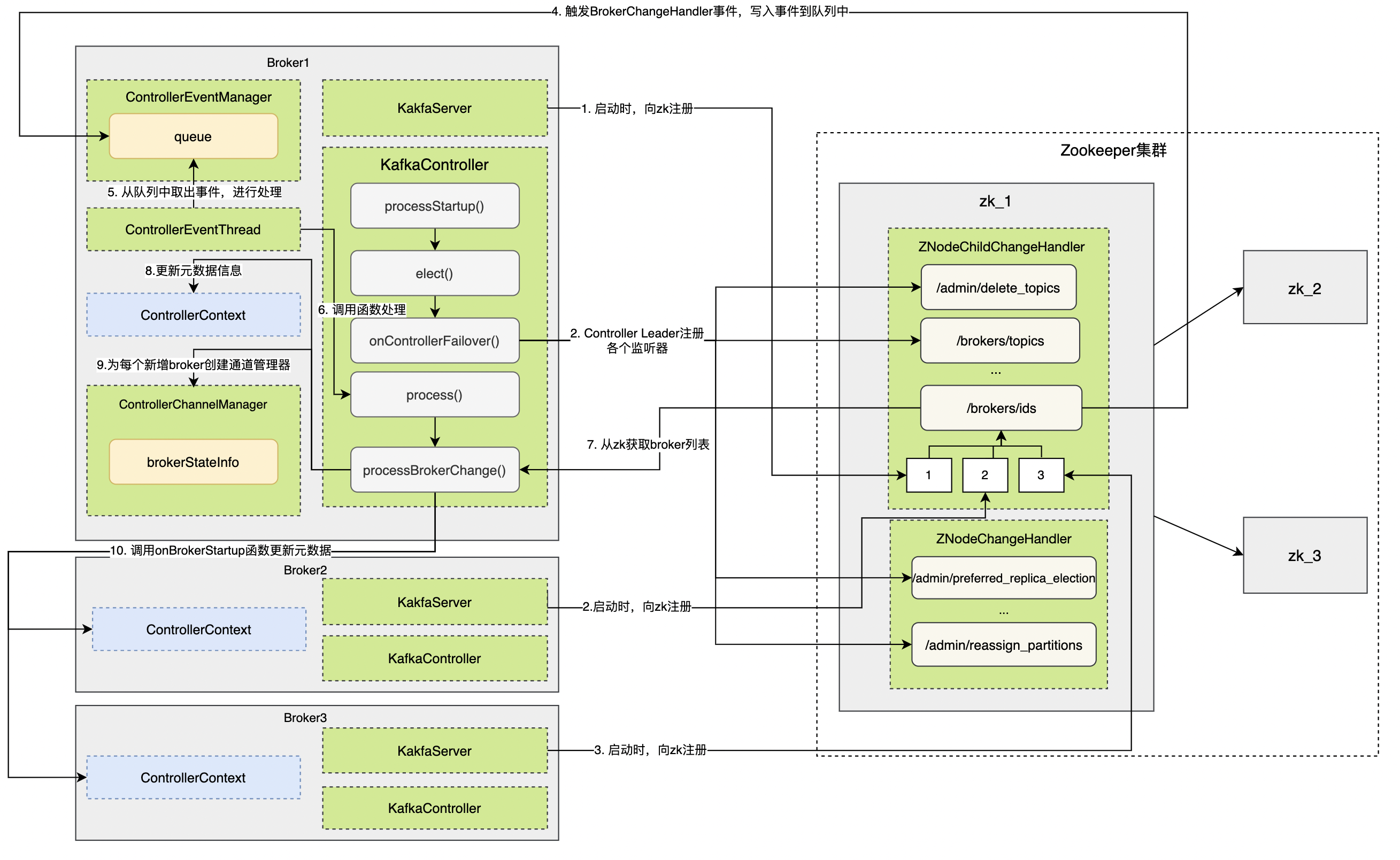
假设Broker1节点先启动,向zookeeper目录
/brokers/ids节点下创建一个名为 broker.id 参数值的临时节点。// kafkaServer.scala override def startup(): Unit = { try { info("starting") ... val brokerInfo = createBrokerInfo val brokerEpoch = zkClient.registerBroker(brokerInfo) ... } } -
接着Broker1节点按照上文controler启动逻辑,执行
processStartup()函数,并进行选举。Broker1从zookeeper获取当前活跃控控制器也就是KafkaController Leader不存在,选举自己为Leader// KafkaContorlller.scala private def elect(): Unit = { // 获取控制器leader Id activeControllerId = zkClient.getControllerId.getOrElse(-1) // 如果leader已经存在,则返回 if (activeControllerId != -1) { debug(s"Broker $activeControllerId has been elected as the controller, so stopping the election process.") return } try { // 创建/controller节点,设置自己的brokerid和epoch版本信息 val (epoch, epochZkVersion) = zkClient.registerControllerAndIncrementControllerEpoch(config.brokerId) controllerContext.epoch = epoch controllerContext.epochZkVersion = epochZkVersion activeControllerId = config.brokerId // 执行当选controller后的后续逻辑: // 1. 注册各类zookeeper事件监听器 // 2. 删除日志路径变更和ISR变更通知 // 3. 初始化集群元信息 // 4. 启动controller通道管理器 // 5. 启动副本状态机和分区状态机 onControllerFailover() } catch { // 如果抢注失败了,代码会抛出异常。 // 这通常表明 Controller 已经被其他 Broker 抢先占据了,那么,此时代码调用 maybeResign 方法去执行卸任逻辑。 ... } } -
Broker2、Broker3节点分别启动,向zookeeper目录
/brokers/ids注册节点信息。一旦发现新增或删除 Broker,/brokers/ids 下的子节点数目一定会发生变化。这会被 Controller 侦测到,进而触发 BrokerChangeHandler 的处理方法,即 handleChildChange 方法。 -
Broker1由于之间注册过BrokerChange事件(基于这种临时节点的机制,Controller 定义了 BrokerChangeHandler 监听器,专门负责监听 /brokers/ids 下的子节点数量变化),所以zookeeper收到Broker1和Broker2节点注册信息后,回调通知Broker1获取事件放入队列
class BrokerChangeHandler(eventManager: ControllerEventManager) extends ZNodeChildChangeHandler { override val path: String = BrokerIdsZNode.path override def handleChildChange(): Unit = { // 获取brokerchange事件 eventManager.put(BrokerChange) } } -
事件最后交由KafkaController处理,并调用
process()函数// KafkaController的process方法, override def process(event: ControllerEvent): Unit = { try { event match { ...... case BrokerChange => processBrokerChange() // 匹配brokerchange事件 } } ...... } -
获取Broker集合列表,执行元数据更新、Broker终止、Broker启动等操作
private def processBrokerChange(): Unit = { // 如果该Broker不是Controller,自然无权处理,直接返回 if (!isActive) return // 第1步:从ZooKeeper中获取集群Broker列表 val curBrokerAndEpochs = zkClient.getAllBrokerAndEpochsInCluster val curBrokerIdAndEpochs = curBrokerAndEpochs map { case (broker, epoch) => (broker.id, epoch) } val curBrokerIds = curBrokerIdAndEpochs.keySet // 第2步:获取Controller当前保存的Broker列表 val liveOrShuttingDownBrokerIds = controllerContext.liveOrShuttingDownBrokerIds // 已重启Broker列表和当前运行中的Broker列表 val newBrokerIds = curBrokerIds.diff(liveOrShuttingDownBrokerIds) val deadBrokerIds = liveOrShuttingDownBrokerIds.diff(curBrokerIds) val bouncedBrokerIds = (curBrokerIds & liveOrShuttingDownBrokerIds) .filter(brokerId => curBrokerIdAndEpochs(brokerId) > controllerContext.liveBrokerIdAndEpochs(brokerId)) val newBrokerAndEpochs = curBrokerAndEpochs.filter { case (broker, _) => newBrokerIds.contains(broker.id) } val bouncedBrokerAndEpochs = curBrokerAndEpochs.filter { case (broker, _) => bouncedBrokerIds.contains(broker.id) } val newBrokerIdsSorted = newBrokerIds.toSeq.sorted val deadBrokerIdsSorted = deadBrokerIds.toSeq.sorted val liveBrokerIdsSorted = curBrokerIds.toSeq.sorted val bouncedBrokerIdsSorted = bouncedBrokerIds.toSeq.sorted info(s"Newly added brokers: ${newBrokerIdsSorted.mkString(",")}, " + s"deleted brokers: ${deadBrokerIdsSorted.mkString(",")}, " + s"bounced brokers: ${bouncedBrokerIdsSorted.mkString(",")}, " + s"all live brokers: ${liveBrokerIdsSorted.mkString(",")}") // 第4步:为每个新增Broker创建与之连接的通道管理器和 // 底层的请求发送线程(RequestSendThread) newBrokerAndEpochs.keySet.foreach(controllerChannelManager.addBroker) // 第5步:为每个已重启的Broker移除它们现有的配套资源 // (通道管理器、RequestSendThread等),并重新添加它们 bouncedBrokerIds.foreach(controllerChannelManager.removeBroker) bouncedBrokerAndEpochs.keySet.foreach(controllerChannelManager.addBroker) // 第6步:为每个待移除Broker移除对应的配套资源 deadBrokerIds.foreach(controllerChannelManager.removeBroker) if (newBrokerIds.nonEmpty) { val (newCompatibleBrokerAndEpochs, newIncompatibleBrokerAndEpochs) = partitionOnFeatureCompatibility(newBrokerAndEpochs) if (!newIncompatibleBrokerAndEpochs.isEmpty) { warn("Ignoring registration of new brokers due to incompatibilities with finalized features: " + newIncompatibleBrokerAndEpochs.map { case (broker, _) => broker.id }.toSeq.sorted.mkString(",")) } controllerContext.addLiveBrokers(newCompatibleBrokerAndEpochs) // 为已重启 Broker 和新增 Broker 调用 onBrokerStartup 方法 onBrokerStartup(newBrokerIdsSorted) } if (bouncedBrokerIds.nonEmpty) { controllerContext.removeLiveBrokers(bouncedBrokerIds) onBrokerFailure(bouncedBrokerIdsSorted) val (bouncedCompatibleBrokerAndEpochs, bouncedIncompatibleBrokerAndEpochs) = partitionOnFeatureCompatibility(bouncedBrokerAndEpochs) if (!bouncedIncompatibleBrokerAndEpochs.isEmpty) { warn("Ignoring registration of bounced brokers due to incompatibilities with finalized features: " + bouncedIncompatibleBrokerAndEpochs.map { case (broker, _) => broker.id }.toSeq.sorted.mkString(",")) } controllerContext.addLiveBrokers(bouncedCompatibleBrokerAndEpochs) onBrokerStartup(bouncedBrokerIdsSorted) } if (deadBrokerIds.nonEmpty) { controllerContext.removeLiveBrokers(deadBrokerIds) // 为待移除 Broker 和已重启 Broker 调用 onBrokerFailure 方法 onBrokerFailure(deadBrokerIdsSorted) } if (newBrokerIds.nonEmpty || deadBrokerIds.nonEmpty || bouncedBrokerIds.nonEmpty) { info(s"Updated broker epochs cache: ${controllerContext.liveBrokerIdAndEpochs}") } }- 执行元数据更新操作:调用 ControllerContext 类的各个方法,更新不同的集群元数据信息。比如需要将新增 Broker 加入到集群元数据,将待移除 Broker 从元数据中移除等。
- 执行 Broker 终止操作:为待移除 Broker 和已重启 Broker 调用 onBrokerFailure 方法。
- 执行 Broker 启动操作:为已重启 Broker 和新增 Broker 调用 onBrokerStartup 方法。
-
给新增和现有Broker同步集群元数据信息
private def onBrokerStartup(newBrokers: Seq[Int]): Unit = { info(s"New broker startup callback for ${newBrokers.mkString(",")}") // 第1步:移除元数据中新增Broker对应的副本集合 newBrokers.foreach(controllerContext.replicasOnOfflineDirs.remove) val newBrokersSet = newBrokers.toSet val existingBrokers = controllerContext. liveOrShuttingDownBrokerIds.diff(newBrokersSet) // 第2步:给集群现有Broker发送元数据更新请求,令它们感知到新增Broker的到来 sendUpdateMetadataRequest(existingBrokers.toSeq, Set.empty) // 第3步:给新增Broker发送元数据更新请求,令它们同步集群当前的所有分区数据 sendUpdateMetadataRequest(newBrokers, controllerContext.partitionLeadershipInfo.keySet) val allReplicasOnNewBrokers = controllerContext.replicasOnBrokers(newBrokersSet) // 第4步:将新增Broker上的所有副本设置为Online状态,即可用状态 replicaStateMachine.handleStateChanges( allReplicasOnNewBrokers.toSeq, OnlineReplica) partitionStateMachine.triggerOnlinePartitionStateChange() // 第5步:重启之前暂停的副本迁移操作 maybeResumeReassignments { (_, assignment) => assignment.targetReplicas.exists(newBrokersSet.contains) } val replicasForTopicsToBeDeleted = allReplicasOnNewBrokers.filter(p => topicDeletionManager.isTopicQueuedUpForDeletion(p.topic)) // 第6步:重启之前暂停的主题删除操作 if (replicasForTopicsToBeDeleted.nonEmpty) { info(s"Some replicas ${replicasForTopicsToBeDeleted.mkString(",")} for topics scheduled for deletion " + s"${controllerContext.topicsToBeDeleted.mkString(",")} are on the newly restarted brokers " + s"${newBrokers.mkString(",")}. Signaling restart of topic deletion for these topics") topicDeletionManager.resumeDeletionForTopics( replicasForTopicsToBeDeleted.map(_.topic)) } // 第7步:为新增Broker注册BrokerModificationsHandler监听器 registerBrokerModificationsHandler(newBrokers) }
移除controller
Broker检测到/controller节点消失了,也就是说整个集群没有Controller Leader。还记得上文controller启动代码吗。每个broker启动都会向zk注册controllerChangeHandler。controller事件如下:
class ControllerChangeHandler(eventManager: ControllerEventManager) extends ZNodeChangeHandler {
override val path: String = ControllerZNode.path
override def handleCreation(): Unit = eventManager.put(ControllerChange)
override def handleDeletion(): Unit = eventManager.put(Reelect)
override def handleDataChange(): Unit = eventManager.put(ControllerChange)
}
可以看到移除节点实际是向事件管理器队列中放入了Reelect事件。此事件执行逻辑:
private def processReelect(): Unit = {
// 可能会执行卸载操作
maybeResign()
// 重新选举
elect()
}
private def maybeResign(): Unit = {
// 非常关键的一步!这是判断是否需要执行卸任逻辑的重要依据!
// 判断该Broker之前是否是Controller
val wasActiveBeforeChange = isActive
// 注册ControllerChangeHandler监听器
zkClient.registerZNodeChangeHandlerAndCheckExistence(controllerChangeHandler)
// 获取当前集群Controller所在的Broker Id,如果没有Controller则返回-1
activeControllerId = zkClient.getControllerId.getOrElse(-1)
// 如果该Broker之前是Controller但现在不是了
if (wasActiveBeforeChange && !isActive) {
onControllerResignation() // 执行卸任逻辑
}
}
如果broker1因为网络原因和zk断开连接,当 Leader 在周期内没有向 ZK 发送报告的话,则认为 Leader 挂了,此时 ZK 删除临时节点:/controller/1
// 这个临时节点是在向zk注册时申请的 def registerControllerAndIncrementControllerEpoch(controllerId: Int): (Int, Int) = { ... def tryCreateControllerZNodeAndIncrementEpoch(): (Int, Int) = { val response = retryRequestUntilConnected( MultiRequest(Seq( // 给临时目录设置数据 CreateOp(ControllerZNode.path, ControllerZNode.encode(controllerId, timestamp), defaultAcls(ControllerZNode.path), CreateMode.EPHEMERAL), SetDataOp(ControllerEpochZNode.path, ControllerEpochZNode.encode(newControllerEpoch), expectedControllerEpochZkVersion))) ) } tryCreateControllerZNodeAndIncrementEpoch() }那么broker2和broker3会收到节点删除事件。这2个节点会重新选举成为新的Leader。假定broker1恢复了通信,broker1会执行
Expire和RegisterBrokerAndReelect事件
private def processRegisterBrokerAndReelect(): Unit = { _brokerEpoch = zkClient.registerBroker(brokerInfo) processReelect() } private def processExpire(): Unit = { activeControllerId = -1 onControllerResignation() }
Controller信息变更
Broker 检测到 /controller 节点数据发生变化,通常表明,Controller“易主”了,这就分为两种情况:
- 如果 Broker 之前是 Controller,那么该 Broker 需要首先执行卸任操作,然后再尝试竞选;
- 如果 Broker 之前不是 Controller,那么,该 Broker 直接去竞选新 Controller。
private def processControllerChange(): Unit = {
maybeResign()
}
Controller网络模型
通过选举机制,让某一个Broker节点成为了Controller,又它来负责集群中各种事件。但是,Controller究竟是如何与集群中其他Broker进行交互,从而实现管理集群元数据等功能的呢?
首先,让我们看看每次新增broker节点后,Controller如何创建新增broker的client连接:
// ControllerChannelManager.scala
// 被processBrokerChange()调用newBrokerAndEpochs.keySet.foreach(controllerChannelManager.addBroker)
// controller对每个新加入的follower创建一个长连接,用于发送ctonroller相关消息更新元数据信息
def addBroker(broker: Broker): Unit = {
// be careful here. Maybe the startup() API has already started the request send thread
brokerLock synchronized {
if (!brokerStateInfo.contains(broker.id)) {
addNewBroker(broker)
startRequestSendThread(broker.id)
}
}
}
private def addNewBroker(broker: Broker): Unit = {
// 为该Broker构造请求阻塞队列
val messageQueue = new LinkedBlockingQueue[QueueItem]
val (networkClient, reconfigurableChannelBuilder) = {
...
// 创建NIO Selector实例用于网络数据传输
val selector = new Selector(
NetworkReceive.UNLIMITED,
Selector.NO_IDLE_TIMEOUT_MS,
metrics,
time,
"controller-channel",
Map("broker-id" -> brokerNode.idString).asJava,
false,
channelBuilder,
logContext
)
// 创建NetworkClient实例
// NetworkClient类是Kafka clients工程封装的顶层网络客户端API
// 提供了丰富的方法实现网络层IO数据传输
val networkClient = new NetworkClient(
selector,
new ManualMetadataUpdater(Seq(brokerNode).asJava),
config.brokerId.toString,
1,
0,
0,
Selectable.USE_DEFAULT_BUFFER_SIZE,
Selectable.USE_DEFAULT_BUFFER_SIZE,
config.requestTimeoutMs,
config.connectionSetupTimeoutMs,
config.connectionSetupTimeoutMaxMs,
ClientDnsLookup.USE_ALL_DNS_IPS,
time,
false,
new ApiVersions,
logContext
)
(networkClient, reconfigurableChannelBuilder)
}
...
// 创建该Broker专属的ControllerBrokerStateInfo实例
// 并将其加入到brokerStateInfo统一管理
brokerStateInfo.put(broker.id, ControllerBrokerStateInfo(networkClient, brokerNode, messageQueue,
requestThread, queueSizeGauge, requestRateAndQueueTimeMetrics, reconfigurableChannelBuilder))
}
protected def startRequestSendThread(brokerId: Int): Unit = {
// 获取指定Broker的专属RequestSendThread实例
val requestThread = brokerStateInfo(brokerId).requestSendThread
if (requestThread.getState == Thread.State.NEW)
// 启动线程
requestThread.start()
}
上节我们学习过broker端kafka网络模型,SocketServer中创建了一个控制面的Acceptor和3个Processor就是用来处理controller连接用的。
以上代码,是由ControllerChannelManager管理,它主要处理两类任务:
- 管理 Controller 与集群 Broker 之间的连接,并为每个 Broker 创建 RequestSendThread 线程实例;
- 将要发送的请求放入到指定 Broker 的阻塞队列中,等待该 Broker 专属的 RequestSendThread 线程进行处理。
现在我们对每个broker都创建了一个NetworkClient,那么controller到底发送哪些请求给follower Broker节点?Controller 会给集群中的所有 Broker(包括它自己所在的 Broker)机器发送网络请求。发送请求的目的,是让 Broker 执行相应的指令。我用一张图,来展示下 Controller 都会发送哪些请求,如下所示
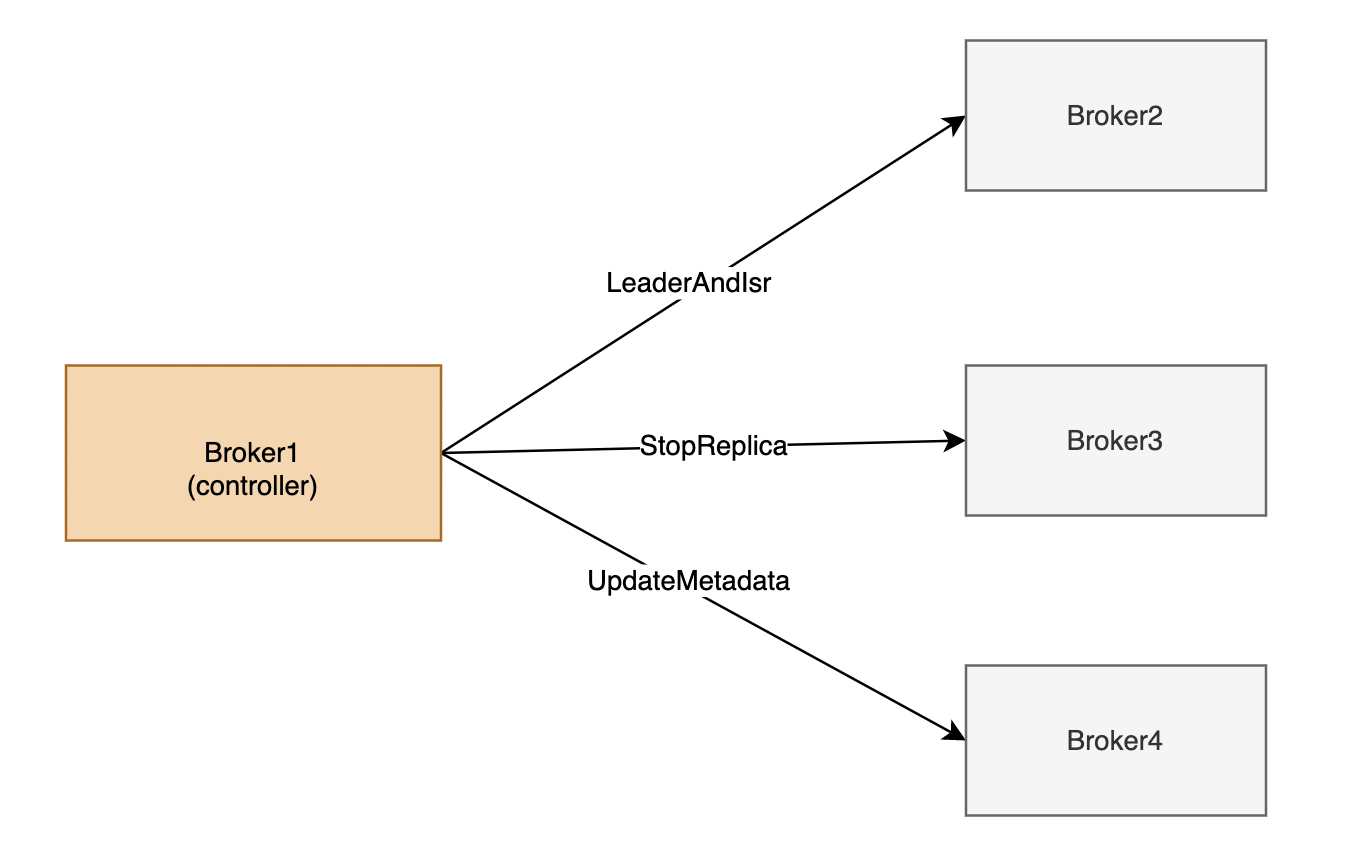
当前,Controller 只会向 Broker 发送三类请求,分别是 LeaderAndIsrRequest、StopReplicaRequest 和 UpdateMetadataRequest
- LeaderAndIsrRequest:最主要的功能是,告诉 Broker 相关主题各个分区的 Leader 副本位于哪台 Broker 上、ISR 中的副本都在哪些 Broker 上。在我看来,它应该被赋予最高的优先级,毕竟,它有令数据类请求直接失效的本领。试想一下,如果这个请求中的 Leader 副本变更了,之前发往老的 Leader 的 PRODUCE 请求是不是全部失效了?因此,我认为它是非常重要的控制类请求。
- StopReplicaRequest:告知指定 Broker 停止它上面的副本对象,该请求甚至还能删除副本底层的日志数据。这个请求主要的使用场景,是分区副本迁移和删除主题。在这两个场景下,都要涉及停掉 Broker 上的副本操
- UpdateMetadataRequest:顾名思义,该请求会更新 Broker 上的元数据缓存。集群上的所有元数据变更,都首先发生在 Controller 端,然后再经由这个请求广播给集群上的所有 Broker。在我刚刚分享的案例中,正是因为这个请求被处理得不及时,才导致集群 Broker 无法获取到最新的元数据信息。
请求最后都会通过RequestSendThread 最重要的是它的 doWork 函数执行逻辑:
override def doWork(): Unit = {
def backoff(): Unit = pause(100, TimeUnit.MILLISECONDS)
val QueueItem(apiKey, requestBuilder, callback, enqueueTimeMs) = queue.take() // 以阻塞的方式从阻塞队列中取出请求
requestRateAndQueueTimeMetrics.update(time.milliseconds() - enqueueTimeMs, TimeUnit.MILLISECONDS) // 更新统计信息
var clientResponse: ClientResponse = null
try {
var isSendSuccessful = false
while (isRunning && !isSendSuccessful) {
try {
// 如果没有创建与目标Broker的TCP连接,或连接暂时不可用
if (!brokerReady()) {
isSendSuccessful = false
backoff() // 等待重试
}
else {
val clientRequest = networkClient.newClientRequest(brokerNode.idString, requestBuilder,
time.milliseconds(), true)
// 发送请求,等待接收Response
clientResponse = NetworkClientUtils.sendAndReceive(networkClient, clientRequest, time)
isSendSuccessful = true
}
} catch {
...
}
}
// 如果接收到了Response
if (clientResponse != null) {
val requestHeader = clientResponse.requestHeader
val api = requestHeader.apiKey
// 此Response的请求类型必须是LeaderAndIsrRequest、StopReplicaRequest或UpdateMetadataRequest中的一种
if (api != ApiKeys.LEADER_AND_ISR && api != ApiKeys.STOP_REPLICA && api != ApiKeys.UPDATE_METADATA)
throw new KafkaException(s"Unexpected apiKey received: $apiKey")
val response = clientResponse.responseBody
if (callback != null) {
callback(response) // 处理回调
}
}
} catch {
case e: Throwable =>
error(s"Controller $controllerId fails to send a request to broker $brokerNode", e)
networkClient.close(brokerNode.idString)
}
}
小结
通过对controller选举机制以及网络模型学习我们可以大致一览controller的全貌。掌握了这些知识,我们再去学习Controller对成员信息管理、主题管理、主题创建/变更、主题删除等应该会比较容易。
让我们再来回顾下前面的内容。所有Broker节点都会创建KafkaController对象,但是只有其中一个Broker会被选举为Controller,整个选举过程通过zk达成共识。Controller选举完后,会针对follower节点的Broker创建客户端,客户端和Broker端之间发送3种类别消息:LeaderAndIsr、StopReplica、UpdateMetadata。