Linux网络命名空间
什么是命名空间
Linux Namespace提供一种内核级别隔离系统资源的方法,通过将系统的全局资源放在不同的Namespace中,来实现资源隔离的目的。不同的Namespace程序,可用享有一份独立的系统资源。
到目前最新的 Linux Kernel 5.6 版内核为止,Linux 名称空间支持以下八种资源的隔离,分别是:
| 名称空间 | 隔离内容 | 内核版本 |
|---|---|---|
| Mount | 隔离文件系统,功能上大致可以类比chroot |
2.4.19 |
| UTS | 隔离主机的Hostname、Domain names | 2.6.19 |
| IPC | 隔离进程间通信的渠道(详见“远程服务调用”中对 IPC 的介绍) | 2.6.19 |
| PID | 隔离进程编号,无法看到其他名称空间中的 PID,意味着无法对其他进程产生影响 | 2.6.24 |
| Network | 隔离网络资源,如网卡、网络栈、IP 地址、端口,等等 | 2.6.29 |
| User | 隔离用户和用户组 | 3.8 |
| Cgroup | 隔离cgroups信息,进程有自己的cgroups的根目录视图(在/proc/self/cgroup 不会看到整个系统的信息)。 |
4.6 |
| Time | 隔离系统时间,2020 年 3 月最新的 5.6 内核开始支持进程独立设置系统时间 | 5.6 |
在本篇文章中,我们主要介绍Linux网络命名空间。
网络命名空间
network namespace 是实现网络虚拟化的重要功能,它能创建多个隔离的网络空间,它们有独自的网络栈信息。处于不同网络命名空间的网络栈是完全隔离的,彼此之间无法通信,就好像“平行宇宙”。通过对网络资源的隔离,就能在一个宿主机上虚拟多个不同的网络环境。每个独立的网络环境包含如下资源:
- 网络设备
- IP地址表
- 路由表
- APR表
- 隧道
- 防火墙
- iptables规则
- 等等
命名空间管理
我们可以使用Linux iproute2系列配置工具中的IP命令来操作网络命名空间。注意:ip命令因为需要修改系统的网络配置,需要由root用户运行。
ip 命令管理的功能很多, 和 network namespace 有关的操作都是在子命令 ip netns 下进行的,可以通过 ``ip netns help` 查看所有操作的帮助信息。
$ ip netns help
Usage: ip netns list
ip netns add NAME
ip netns attach NAME PID
ip netns set NAME NETNSID
ip [-all] netns delete [NAME]
ip netns identify [PID]
ip netns pids NAME
ip [-all] netns exec [NAME] cmd ...
ip netns monitor
ip netns list-id [target-nsid POSITIVE-INT] [nsid POSITIVE-INT]
NETNSID := auto | POSITIVE-INT
默认情况下,使用 ip netns 是没有网络 namespace 的,所以 ip netns ls 命令看不到任何输出。
$ ip netns ls
创建 network namespace 也非常简单,直接使用 ip netns add 后面跟着要创建的 namespace 名称。如果相同名字的 namespace 已经存在,命令会报 Cannot create namespace 的错误。
$ ip netns add ns1
$ ip netns ls
ns1
$ ip netns add ns1
Cannot create namespace file "/var/run/netns/ns1": File exists
可见,ip netns 命令创建的 network namespace 会出现在 /var/run/netns/ 目录下,如果需要管理其他不是 ip netns 创建的 network namespace,只要在这个目录下创建一个指向对应 network namespace 文件的链接就行。
有了自己创建的 network namespace,我们还需要看看它里面有哪些东西。对于每个 network namespace 来说,它会有自己独立的网卡、路由表、ARP 表、iptables 等和网络相关的资源。ip 命令提供了 ip netns exec 子命令可以在对应的 network namespace 中执行命令。
在命名空间中执行命令:
$ ip netns exec <name> <command>
也可以先通过bash命令进入内部的shell界面,然后执行各种命令:
$ ip netns exec <name> bash
执行
bash命令了之后,后面所有的命令都是在这个 network namespace 中执行的,好处是不用每次执行命令都要把ip netns exec NAME补全,缺点是你无法清楚知道自己当前所在的shell,容易混淆。比如下面的例子:
$ ip netns exec ns1 ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 $ ip netns exec ns1 bash $ ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 $ exit exit
更新:通过修改 bash 的前缀信息可以区分不同 shell,操作如下:
$ ip netns exec ns1 bash --rcfile <(echo "PS1=\"ns ns1> \"")
ns ns1> ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
ns ns1>
命名空间配置
上面命令ip addr可以看到,新的网络命名空间将有一个环回设备,但没有其他网络设备。每个namespace在创建时会自动创建一个lo的interface,它的作用和linux系统中默认看到的lo一样,都是为了实现loopback通信。首次创建时,lo环回设备是关闭的,因此即使ping环回设备也会失败:
$ ip netns exec ns1 ping 127.0.0.1
connect: Network is unreachable
可使用如下命令开启lo设备:
$ ip netns exec ns1 ip link set lo up
$ ip netns exec ns1 ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
$ ip netns exec ns1 ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.028 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.027 ms
网络命名空间之间通信
有了不同 network namespace 之后,也就有了网络的隔离,但是如果它们之间没有办法通信,也没有实际用处。由于不能将物理设备(连接到实际硬件的设备)分配给除 root 外的命名空间。相反,可以创建虚拟网络设备(例如虚拟以太网)并将其分配给命名空间。这些虚拟设备允许命名空间内的进程通过网络进行通信;配置、路由等决定它们可以与谁通信。
Veth设备对
veth设备对全称虚拟以太网(Virtual Ethernet), 引入veth设备对是为了在不同的网络命名空间之间通信,利用它可以直接将两个命名空间连接起来。veth设备对是一种主流的虚拟网卡方案。
由于要连接两个不同的命名空间,veth实际上不是一个设备,而是成对出现的,因而也常被称为veth pair。直接把 veth 比喻成是虚拟网卡其实并不十分准确,如果要和物理设备类比,它应该相当于的一对物理网卡。,并且中间有一跟由交叉网线连接。
额外知识:直连线序、交叉线序
交叉网线是指一头是 T568A 标准,另外一头是 T568B 标准的网线。直连网线则是两头采用同一种标准的网线。
网卡对网卡这样的同类设备需要使用交叉线序的网线来连接,网卡到交换机、路由器就采用直连线序的网线,不过现在的网卡大多带有线序翻转功能,直连线也可以网卡对网卡地连通了。
既然是一对网卡,那么我们将其中一端称为另一端的peer。在veth设备的一端发送数据时,它会将数据直接发送到另一端,并触发另一端的接收操作,如下图。
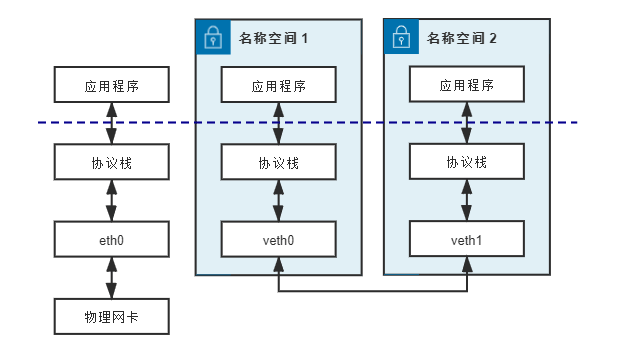
veth设备对管理
首先,我们创建了2个不同命名空间,ns1和ns2:
$ ip netns ls
ns2
ns1
然后,使用ip link add <interface-name> type veth peer name <interface-name>来创建一对veth pair,需要注意的是vets pair无法单独存在,删除其中一个,另一个也会自动消失。
# 创建一对名为 veth0 和 veth1 的 veth 接口。
$ ip link add veth0 type veth peer name veth1
小知识: 也可以直接输入命令
ip link add type veth, 会创建名字为veth0和veth1两个网络接口,名字后面的数字是系统自动生成的
使用ip link show <interface-name>或者ip link show查看网络接口,可以看到默认的命名空间下存在两个设备,一个是veth0 ,它的peer是 veth1 。
# 确认veth0已经创建
$ ip link show veth0
30: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether b6:b1:8b:32:6e:76 brd ff:ff:ff:ff:ff:ff
# 确认veth1已经创建
$ ip link show veth1
29: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAUL$T group default qlen 1000
link/ether c6:8b:41:94:9c:0b brd ff:ff:ff:ff:ff:ff
接下来,我们要把这对veth pair分别放到已经存在的ns1、ns2两个命名空间里,使用命令:ip link set <device-name> netns <interface-name>:
$ ip link set veth0 netns ns1
$ ip link set veth0 netns ns2
# 在ns1网络命名空间可以看到veth0,符合预期
$ ip netns exec ns1 ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
35: veth0@if36: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ea:54:cc:d8:5f:ed brd ff:ff:ff:ff:ff:ff link-netns ns2
# 在ns2网络命名空间可以看到veth1,符合预期
$ ip netns exec ns2 ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
36: veth1@if35: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 32:bb:b6:fc:87:ff brd ff:ff:ff:ff:ff:ff link-netns ns1
可以看到,两个不同命名空间各自有一个veth的"网线头",各显示为一个Device
额外知识:在Docker实现了,它除了将veth放入容器内,还将它的名字改成eth0,简直以假乱真,让人以为它是一个本地网卡
veth设备对如何查看对端
一旦将veth设备对的对端放入另一个命名空间,在本命名空间中就看不到它了。那么我们怎么知道这个veth设备的对端在哪里?可以使用ethtool工具查看
$ ip netns exec ns1 ethtool -S veth0
NIC statistics:
peer_ifindex: 36
得知另一端接口设备的序列号是36,我们再到命名空间ns2中查看序列号为36的设备
$ ip netns exec ns2 ip link | grep 36
36: veth1@if35: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
veth设备对通信
现在,两个命名空间可以通信了吗?不行,因为它们还没有分配任何IP地址,只有一个lo地址。要分配一个新的 IP 地址范围到一个接口,使用 ip addr add <ip-address-range> dev <device-name> 命令。现在将2个命名空间分别分配IP地址:
# 将 veth0 接口 up 起来
$ ip netns exec ns1 ip link set veth0 up
# 将 10.0.1.1/24 IP 地址范围分配给 veth0 接口
$ ip netns exec ns1 ip addr add 10.0.1.1/24 dev veth0
# 将 veth1 接口 up 起来
$ ip netns exec ns2 ip link set veth1 up
# 将 10.0.2.1/24 IP 地址范围分配给 veth0 接口
$ ip netns exec ns2 ip addr add 10.0.1.2/24 dev veth1
现在我们再来尝试ping下对方的veth接口
# 在ns1中试着连通ns2命名空间IP地址
$ ip netns exec ns1 ping -c 2 10.0.1.2
PING 10.0.1.2 (10.0.1.2) 56(84) bytes of data.
64 bytes from 10.0.1.2: icmp_seq=1 ttl=64 time=0.031 ms
64 bytes from 10.0.1.2: icmp_seq=2 ttl=64 time=0.037 ms
--- 10.0.2.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1005ms
rtt min/avg/max/mdev = 0.031/0.034/0.037/0.003 ms
可以看到已经通啦!!我们创建的网络拓扑结构如下所示:
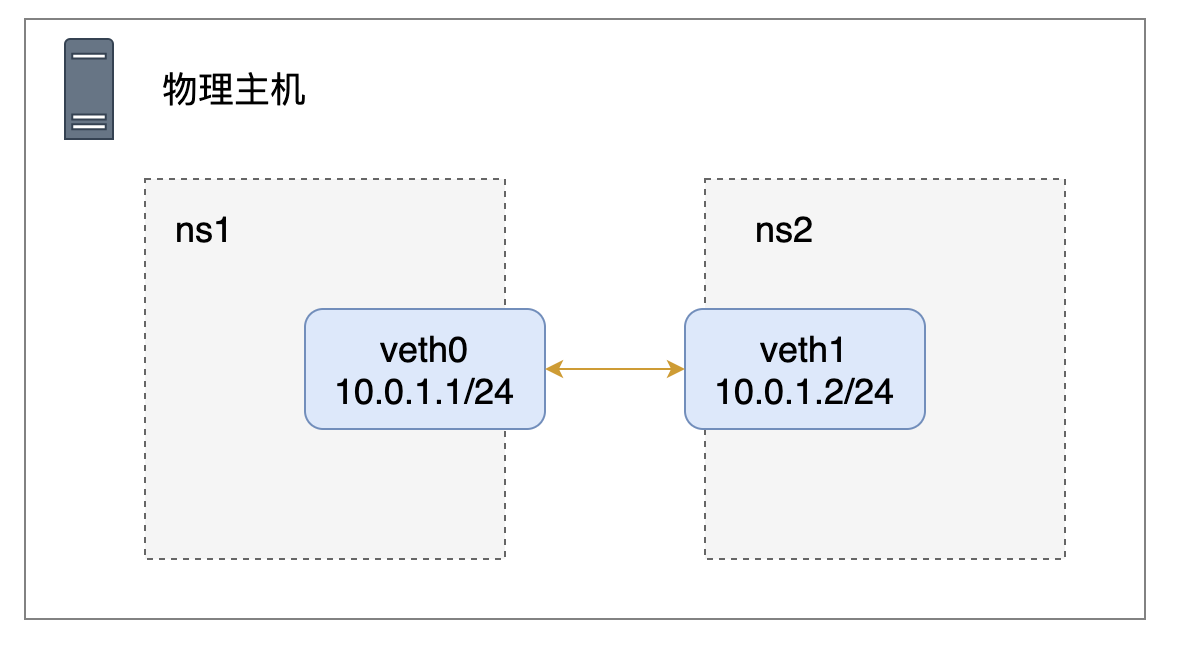
此外我们还可以使用 tcpdump 来捕获两个网络命名空间之间传输的数据包。
$ ip netns exec ns1 tcpdump -i veth0 icmp -l
dropped privs to tcpdump
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
18:49:58.847541 IP VM-8-12-centos > 10.0.1.2: ICMP echo request, id 21555, seq 1, length 64
18:49:58.847558 IP 10.0.1.2 > VM-8-12-centos: ICMP echo reply, id 21555, seq 1, length 64
18:49:59.862635 IP VM-8-12-centos > 10.0.1.2: ICMP echo request, id 21555, seq 2, length 64
18:49:59.862658 IP 10.0.1.2 > VM-8-12-centos: ICMP echo reply, id 21555, seq 2, length 64
18:50:00.886633 IP VM-8-12-centos > 10.0.1.2: ICMP echo request, id 21555, seq 3, length 64
18:50:00.886653 IP 10.0.1.2 > VM-8-12-centos: ICMP echo reply, id 21555, seq 3, length 64
18:50:01.910636 IP VM-8-12-centos > 10.0.1.2: ICMP echo request, id 21555, seq 4, length 64
18:50:01.910659 IP 10.0.1.2 > VM-8-12-centos: ICMP echo reply, id 21555, seq 4, length 64
^C
20 packets captured
20 packets received by filter
0 packets dropped by kernel
测试TCP连接
首先安装工具nc
$ yum -y install nc
然后在 ns1 命名空间使用 nc 命令启动一个端口为8080 TCP 服务器,然后从 ns2 网络命名空间发起一个 TCP 握手连接。
$ ip netns exec ns1 nc -l 10.0.1.1 8080 -v
Ncat: Version 7.70 ( https://nmap.org/ncat )
Ncat: Listening on 10.0.1.1:8080
然后重新开一个终端进行连接,使用 nc 从 ns2 发起 TCP 握手:
$ ip netns exec ns2 nc -4t 10.0.1.1 8080 -v
Ncat: Version 7.70 ( https://nmap.org/ncat )
Ncat: Connected to 10.0.1.1:8080.
# 这个时候正常会在ns1命名空间下前面的服务中看到连接状态
$ ip netns exec ns1 nc -l 10.0.1.1 8080 -v
Ncat: Version 7.70 ( https://nmap.org/ncat )
Ncat: Listening on 10.0.1.1:8080
Ncat: Connection from 10.0.1.2.
Ncat: Connection from 10.0.1.2:54292.
一旦 TCP 连接建立,我们就可以从 ns2 向 ns1 发送测试消息了。
$ ip netns exec ns2 nc -4t 10.0.1.1 8080 -v
Ncat: Version 7.70 ( https://nmap.org/ncat )
Ncat: Connected to 10.0.1.1:8080.
test1
test2
此时我们在 ns1 这边的服务器端也会收到发送的消息。
$ ip netns exec ns1 nc -l 10.0.1.1 8080 -v
Ncat: Version 7.70 ( https://nmap.org/ncat )
Ncat: Listening on 10.0.1.1:8080
Ncat: Connection from 10.0.1.2.
Ncat: Connection from 10.0.1.2:54292.
test
test1
test2
网桥
简介
虽然veth设备对可以实现两个网络命名空间之间的通信,但是当多个网名命名空间需要通信时,就无能为力了。前文说过可以把veth比如成虚拟网卡。既然存在虚拟网卡,那么很自然也思考是否能让网卡接入到交换机里,实现多个网络命名空间互相通信。
Linux Bridge便是 Linux 系统下的虚拟化交换机,虽然它以“网桥”(Bridge)而不是“交换机”(Switch)为名,然而使用过程中,你会发现 Linux Bridge 的目的看起来像交换机,功能使用起来像交换机、程序实现起来也像交换机,实际就是一台虚拟交换机。所以网桥是一个二层的虚拟网络设备,通过把若干个网络接口“连接”起来,以使得网络接口之间的报文能够互相转发。网桥能够解析收发的报文,读取目标MAC地址的信息,和自己记录的MAC表结合,来决策报文的转发目标网络接口。
现在,让我们通过一个例子来演示网桥的实现。假设,我们有3个命名空间和一个网桥,那么我们如何让3个命名空间之间通信呢?
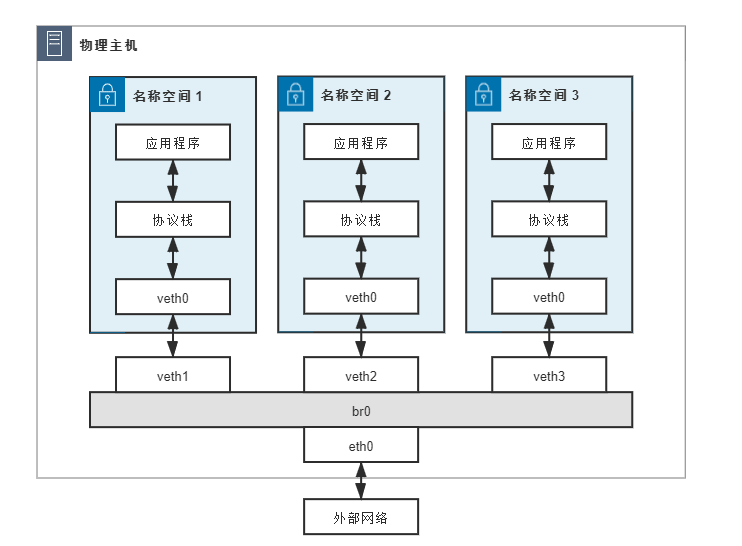
上图配置如下:
- 网桥br0:位于默认网络命名空间,也可以当做一张网卡
- 命名空间:三个网络名称空间,分别编号为 1、2、3,均使用 veth pair 接入网桥,且有如下配置
- 命名空间内的网卡名为 veth0,在网桥一端网卡名为 veth1、veth2、veth3
- 三个命名空间的veth0网卡分配IP地址:10.0.1.1/24,10.0.1.2/24,10.0.1.3/24
网桥通信
-
网桥由
brctl命令创建和管理,所以我们先检查下是否有安装# 查看bridge $ brctl show -bash: brctl: command not found # 如果没有可以通过如下命令进行安装 yum -y install bridge-utils -
接着我们来创建需要的 bridge,简单起见名字就叫做
br0。# 创建一个网桥,通过命令:brctl addbr <bridge-name> 也可以通过:ip netns exec ns1 ping -c 3 10.1.1.2 $ brctl addbr br0 # 设置网桥状态为up,即开启 $ ip link set br0 up # 查看网络台 $ brctl show bridge name bridge id STP enabled interfaces br0 8000.000000000000 no -
按照上文,创建3个命名空间,设置网络拓扑
# 创建命名空间 $ ip netns add ns1 $ ip netns add ns2 $ ip netns add ns3 # 开启回环 $ ip netns exec ns1 ip link set lo up $ ip netns exec ns2 ip link set lo up $ ip netns exec ns3 ip link set lo up # 创建veth pair设备对ns-veth-1、veth1,把ns-veth-1放到ns1命名空间中,修改名称为veth0 # 设置veth0 IP地址10.1.1.1/24并激活网卡 $ ip link add ns-veth-1 type veth peer name veth1 $ ip link set ns-veth-1 netns ns1 $ ip netns exec ns1 ip link set dev ns-veth-1 name veth0 $ ip netns exec ns1 ip addr add 10.0.1.1/24 dev veth0 $ ip netns exec ns1 ip link set veth0 up # 创建veth pair设备对ns-veth-2、veth2,把ns-veth-2放到ns2命名空间中,修改名称为veth0 # 设置veth0 IP地址10.1.1.2/24并激活网卡 $ ip link add ns-veth-2 type veth peer name veth2 $ ip link set ns-veth-2 netns ns2 $ ip netns exec ns2 ip link set dev ns-veth-2 name veth0 $ ip netns exec ns2 ip addr add 10.0.1.2/24 dev veth0 $ ip netns exec ns2 ip link set veth0 up # 创建veth pair设备对ns-veth-3、veth3,把ns-veth-3放到ns3命名空间中,修改名称为veth0 # 设置veth0 IP地址10.1.1.3/24并激活网卡 $ ip link add ns-veth-3 type veth peer name veth3 $ ip link set ns-veth-3 netns ns3 $ ip netns exec ns3 ip link set dev ns-veth-3 name veth0 $ ip netns exec ns3 ip addr add 10.0.1.3/24 dev veth0 $ ip netns exec ns3 ip link set veth0 up -
分别把veth1、veth2、veth3连接到创建的bridge上,并启动它:
# veth1绑定到br0网桥上,并激活网卡 $ ip link set dev veth1 master br0 $ ip link set dev veth1 up # veth2绑定到br0网桥上,并激活网卡 $ ip link set dev veth2 master br0 $ ip link set dev veth2 up # veth3绑定到br0网桥上,并激活网卡 $ ip link set dev veth3 master br0 $ ip link set dev veth3 up -
通过bridge命令(也是iproutes自带的命令)来查看bridge管理的link信息
$ bridge link 38: veth1@if39: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2 40: veth2@if41: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2 42: veth3@if43: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2 -
最后,通过ping命令来测试网络的连通性
$ ip netns exec ns1 ping -c 3 10.0.1.2 PING 10.0.1.2 (10.0.1.2) 56(84) bytes of data. 64 bytes from 10.0.1.2: icmp_seq=1 ttl=64 time=0.040 ms 64 bytes from 10.0.1.2: icmp_seq=2 ttl=64 time=0.034 ms 64 bytes from 10.0.1.2: icmp_seq=3 ttl=64 time=0.045 ms --- 10.0.1.2 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 1999ms rtt min/avg/max/mdev = 0.034/0.039/0.045/0.008 ms -
通过上面的试验,我们验证了可以使用Linux bridge来将多个namespace连接到同一个二层网络中。你可能注意到,在分配IP地址的时候,我们只为veth在namespace中那一端的虚拟网卡分配了地址,而没有为加入bridge那一端分配地址。这是因为bridge是工作在二层上的,只会处理以太包,包括ARP解析,以太数据包的转发和泛洪;并不会进行三层(IP)的处理,因此不需要三层的IP地址。
-
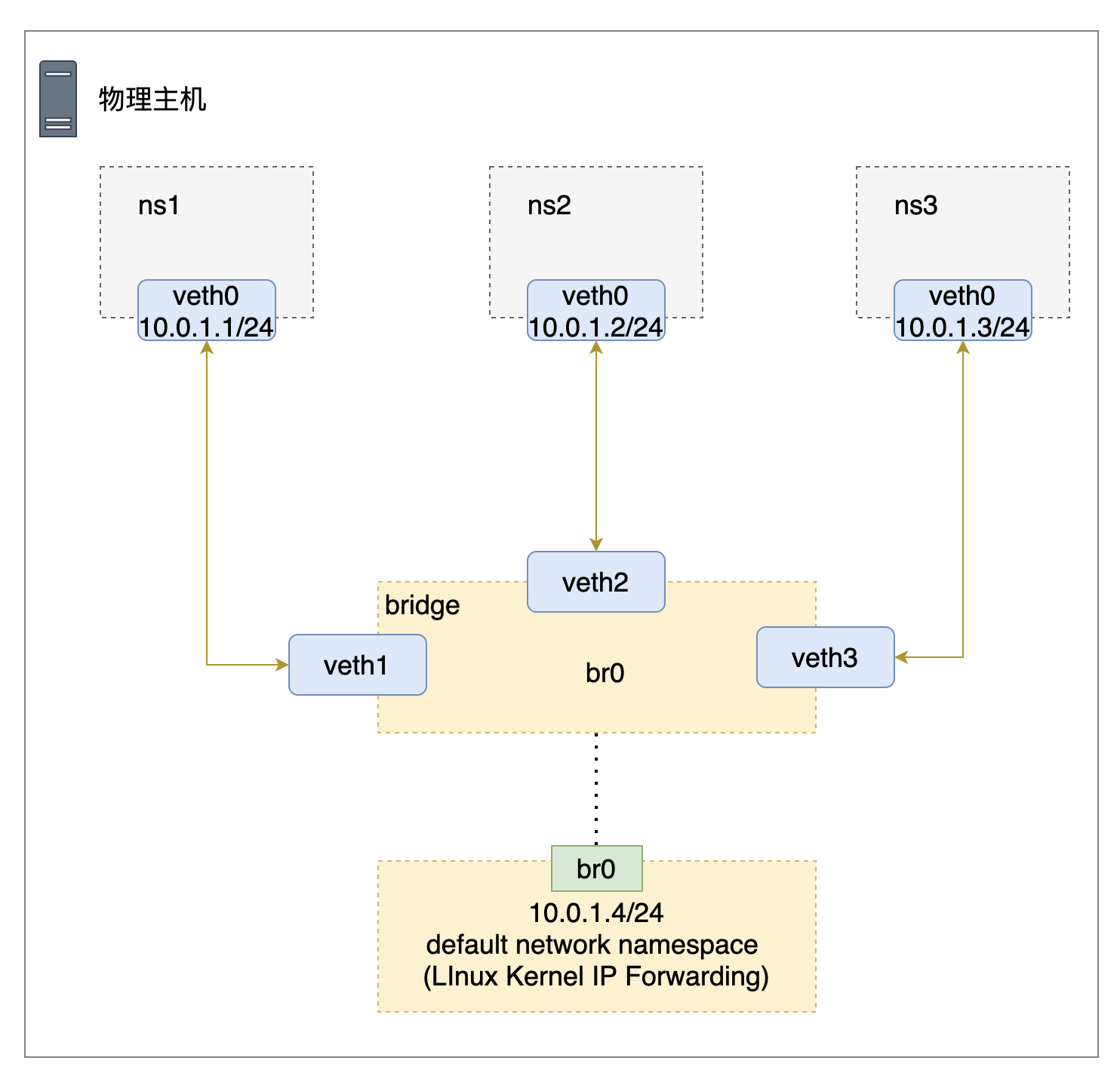
我们创建的网络拓扑结构如下所示
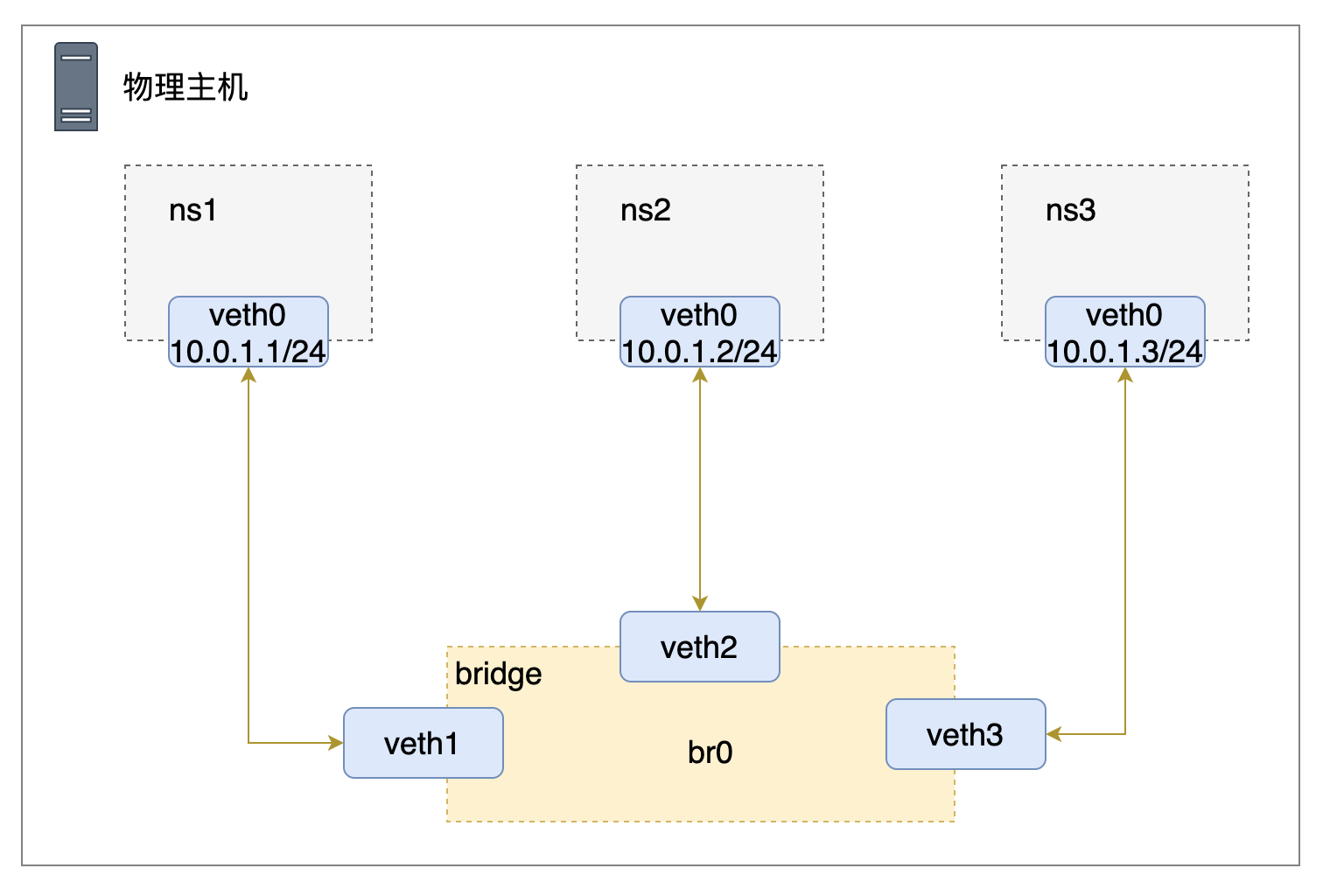
与物理主机通信
前面在介绍Linux bridge时我们讲到,从网络角度上来说,bridge是一个二层设备,因此并不需要设置IP。但Linux bridge虚拟设备比较特殊:我们可以认为bridge自带了一张网卡,这张网卡在主机上显示的名称就是bridge的名称。这张网卡在bridge上,因此可以和其它连接在bridge上的网卡和namespace进行二层通信;同时从主机角度来看,虚拟bridge设备也是主机default network namespace上的一张网卡,在为该网卡设置了IP后,可以参与主机的路由转发。
通过给bridge设置一个IP地址,并将该IP设置为namespace的缺省网关,可以让namespace和主机进行网络通信。
$ ip addr add 10.0.1.4/24 dev br0
$ ping -c 3 10.0.1.1
PING 10.0.1.1 (10.0.1.1) 56(84) bytes of data.
64 bytes from 10.0.1.1: icmp_seq=1 ttl=64 time=0.049 ms
64 bytes from 10.0.1.1: icmp_seq=2 ttl=64 time=0.027 ms
64 bytes from 10.0.1.1: icmp_seq=3 ttl=64 time=0.033 ms
--- 10.0.1.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1999ms
rtt min/avg/max/mdev = 0.027/0.036/0.049/0.010 ms
相关网络拓扑如下图:
基于Linux Route路由通信
Linux系统包含一个完整的路由功能。当IP层在处理数据发送或者转发时,会使用路由表来决定发往哪里。在通常情况下,如果主机与目的主机直接相连,那么主机可以直接发送IP报文到目的主机,这个过程比较简单;如果主机与目的主机没有直接相连,那么主机会将IP报文发送给默认的路由器,然后由路由器来决定往哪发送IP报文。
路由器与交换机的区别在于,交换机只能通过二层转发和在同一个ip网段下转发。而Route路由器是可以通过三层进行转发的,也就是通过ip进行转发,并且可以通过跨网段进行转发。
路由表中的数据一般是以条目形式存在的。一个典型的路由表条目通常包含以下主要的条目项:
- 目的IP地址:此子端表示目标的IP地址
- 下一个路由器的IP地址:下一个路由器地址用来转发在相应接口接收到的IP数据报文
- 标志:从标志中判断目的IP地址是一个主机地址还是网络地址;下一个路由器是一个真实的路由器还是一个直接相连的接口
- 网络接口规范:为一些数据报文的网络接口规范
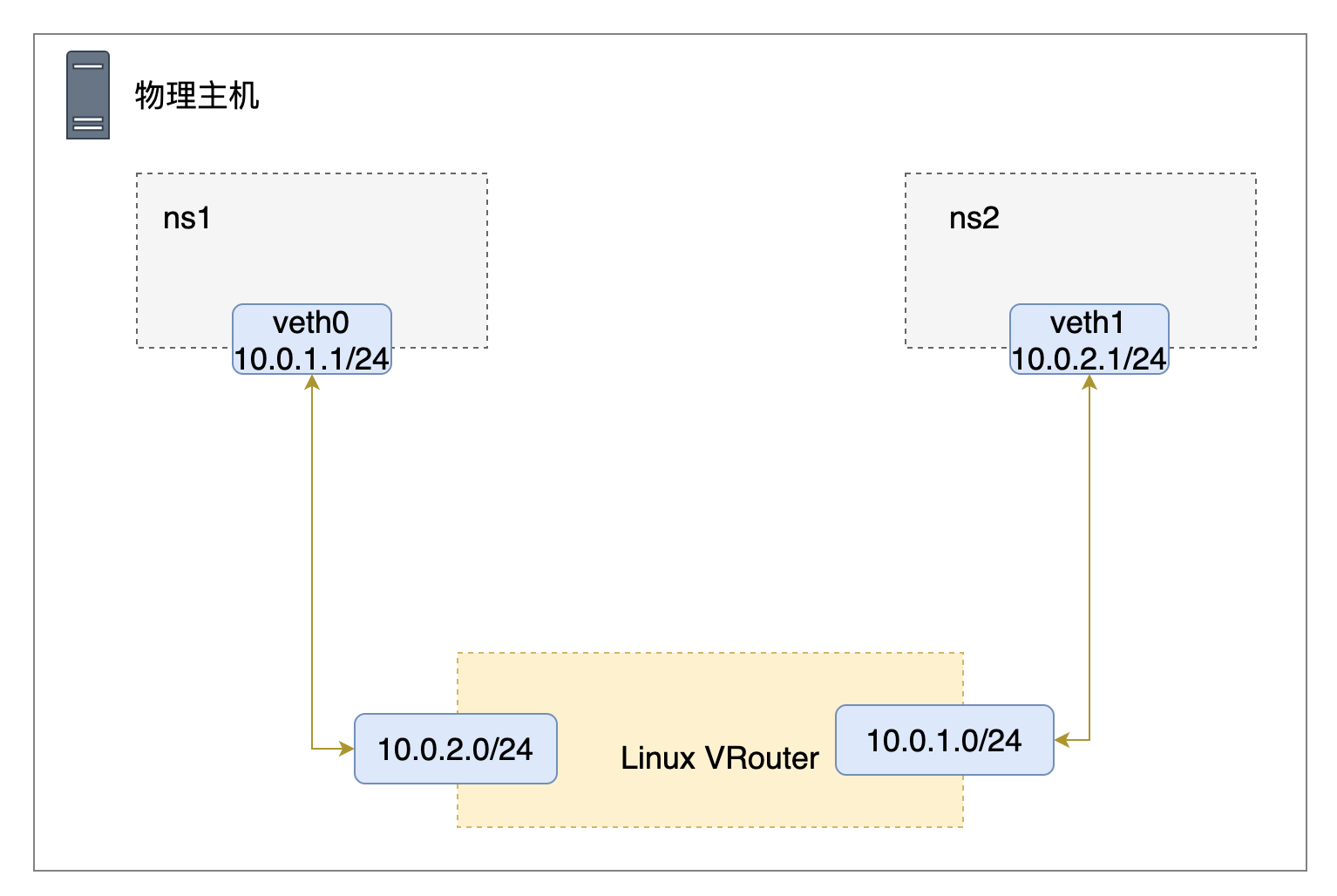
接下来我们以一个具体案例模拟Linux Route路由器跨网段的转发请求。现在假定我们有2个命名空间ns1、ns2,它们属于不同子网:10.0.1.1/24和10.0.2.1/24,那么如何让2个子网之间通信呢?
# 将 veth0 接口 up 起来
$ ip netns exec ns1 ip link set veth0 up
# 将 10.0.1.1/24 IP 地址范围分配给 veth0 接口
$ ip netns exec ns1 ip addr add 10.0.1.1/24 dev veth0
# 使用ping验证在当前命名空间下是否能ping通
$ ip netns exec ns1 ping -c 2 10.0.1.1
PING 10.0.1.1 (10.0.1.1) 56(84) bytes of data.
64 bytes from 10.0.1.1: icmp_seq=1 ttl=64 time=0.015 ms
64 bytes from 10.0.1.1: icmp_seq=2 ttl=64 time=0.028 ms
--- 10.0.1.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1014ms
rtt min/avg/max/mdev = 0.015/0.021/0.028/0.008 ms
# 将 veth1 接口 up 起来
$ ip netns exec ns2 ip link set veth1 up
# 将 10.0.2.1/24 IP 地址范围分配给 veth0 接口
$ ip netns exec ns2 ip addr add 10.0.2.1/24 dev veth1
# 使用ping验证在当前命名空间下是否能ping通
$ ip netns exec ns2 ping -c 2 10.0.2.1
PING 10.0.2.1 (10.0.2.1) 56(84) bytes of data.
64 bytes from 10.0.2.1: icmp_seq=1 ttl=64 time=0.015 ms
64 bytes from 10.0.2.1: icmp_seq=2 ttl=64 time=0.028 ms
--- 10.0.2.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1048ms
rtt min/avg/max/mdev = 0.015/0.021/0.028/0.008 ms
可以看到,最每个 namespace 中,在配置玩 ip 之后,还自动生成了对应的路由表信息。现在,使用 ping 命令验证它们之间的连通性:
$ ip netns exec ns1 ping -c 2 10.0.2.1
connect: Network is unreachable
$ ip netns exec ns2 ping -c 2 10.0.1.1
connect: Network is unreachable
虽然在上面的两个网络空间内可以各自访问自己,但是他们互相之间是不能 ping 通的。因为veth0和veth1配置了不同的子网,所以互相直接不通很可能和路由有关。下面我们使用IP命令来调试下,我们可以通过ip route get 命令来确定一个数据包所走的路由
$ ip netns exec ns1 ip route get 10.0.2.0
RTNETLINK answers: Network is unreachable
$ ip netns exec ns2 ip route get 10.0.1.0
RTNETLINK answers: Network is unreachable
我们可以看到都是网络不可达,我们来检查下两个网络命名空间中的路由表信息。
# 查看ns1命名空间路由信息
$ ip netns exec ns1 ip route
10.0.1.0/24 dev veth0 proto kernel scope link src 10.0.1.1
# 查看ns2命名空间路由信息
$ ip netns exec ns2 ip route
10.0.2.0/24 dev veth1 proto kernel scope link src 10.0.2.1
看到路由表是不是很清晰了,两个网络命名空间的路由表都只有各自 IP 范围的路由条目,并没有通往其他子网的路由,所以当然不能互通了,要解决也很简单,可以使用 ip route add 命令在路由表中插入新的路由条目是不是就可以了。
# 更新 veth0 路由表,添加一条通往 10.0.2.0/24 的路由
$ ip netns exec ns1 ip route add 10.0.2.0/24 dev veth0
# 确认发往 10.0.2.0/24 的数据包被路由到 veth0
$ ip netns exec ns1 ip route get 10.0.2.0
10.0.2.0 dev veth0 src 10.0.1.1 uid 0
cache
# 同样更新 veth1 路由表,添加一条通往 10.0.1.0/24 的路由
$ ip netns exec ns2 ip route add 10.0.1.0/24 dev veth1
# 确认发往 10.0.1.0/24 的数据包被路由到 veth1
$ ip netns exec ns2 ip route get 10.0.1.0
10.0.1.0 dev veth1 src 10.0.2.1 uid 0
cache
现在,我们在各自的网络命名空间中添加了对方的路由信息,现在我们再来尝试ping下对方的veth接口
# 查看ns1命名空间路由信息
$ ip netns exec ns1 ip route
10.0.1.0/24 dev veth0 proto kernel scope link src 10.0.1.1
10.0.2.0/24 dev veth0 scope link
# 在ns1中试着连通ns2命名空间IP地址
$ ip netns exec ns1 ping -c 2 10.0.2.1
PING 10.0.1.2 (10.0.2.1) 56(84) bytes of data.
64 bytes from 10.0.2.1: icmp_seq=1 ttl=64 time=0.031 ms
64 bytes from 10.0.2.1: icmp_seq=2 ttl=64 time=0.037 ms
--- 10.0.2.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1005ms
rtt min/avg/max/mdev = 0.031/0.034/0.037/0.003 ms
可以看到已经通啦!!我们创建的网络拓扑结构如下所示:
小结
Linux网络虚拟化技术(veth设备对、网桥、路由等)是云原生Kubernetes网络模型设计的基础:
- veth设备对类似2个虚拟网卡通过一个交叉网线直连,在veth设备的一端发送数据时,它会将数据直接发送到另一端,并触发另一端的接收操作。
- 网桥类似一个二层虚拟交换机,通过把若干个网络接口“连接”起来,以使得网络接口之间的报文能够互相转发。网桥只能通过二层转发和在同一个ip网段下转发。
- 路由是在IP层处理数据发送和转发,主要通过路由表实现,是通过三层转发实现。