事务的基本原理
ACID理论
ACID理论是一套指导原则,是指数据库在写入或更新过程中,为了保证事务是正确可靠的,所必须具备的四个特性:
-
**原子性(atomicity):**事务中的每个语句(读取、写入、更新或删除数据)都被视为一个单元。要么全部执行、要么全不执行(如果有任一语句执行失败,需要整体回滚)
-
**一致性(consistency):**指事务必须使数据库从一个一致性状态变换到下一种一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态
-
**隔离性(isolation):**当多个用户并发访问数据库时,比如操作同一张表,数据库为每一个用户开启的的事务,不能被其他事务操作所干扰,多个并发事务之间要相互隔离
-
**持久性(durability):**一个事务一旦被提交,那么对数据库中的数据改变是永久性的,即使在数据库遇到故障情况下也不会丢失事务提交的操作
原子性(Atomicity)
原子性也被称为”全执行或全不执行规则“。它非常好理解,既整个事务要么全部执行,要么根本不执行,不会存在部分执行情况。它涉及到以下两个操作:
- 中止: 如果事务中止,则对数据库所做的更改是不可见的
- 提交:如果事务提交,所做的更改都是可见的
考虑以下由T1和T2组成的事务T: 将 100 从账户X转移到账户Y。
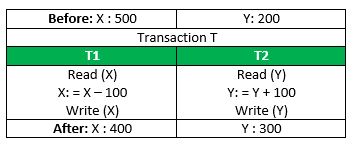
如果交易在T1完成之后但在T2完成之前失败(例如,在write(X)之后但在write(Y)之前),则该金额已从X中扣除但未添加到Y中。这会导致数据库状态不一致。因此,事务必须全部执行,以保证数据库状态的正确性。
一致性(Consistency)
一致性指必须维护完整性约束,以使数据库在事务前后保证一致。参考上面的例子: 交易T出现之前的总计= 500 + 200 = 700。 T 发生后的总数= 400 + 300 = 700。也就是说不管账号X和Y之间如何转账,转几次帐,双方总金额必定是700。也就是交易必须满足总金额一致性的完整性约束。
如果在转账过程中,仅完成从账号X中扣款,但是从账号Y中新增出现失败。这种情况即无法保证原子性,那么数据一致性约束也就被打破了。可见,事务的一致性和原子性是密切相关的,原子性的破坏可能导致数据库一致性约束被破坏。
隔离性(Isolation)
该属性确保多个事务可以同时发生,而不会导致数据库状态不一致。当有多个事务同时操作同一张表同一份数据时,每个事务中的特定更改写入内存或已提交前,该事务中发生的更改对任何其他事务都是不可见的。
现在假设数值X=500,Y=500,考虑下面两个事务T和T“
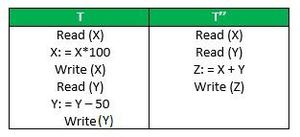
- 事务T:通过计算
X+Y = 50000+450=50450 - 事务T“:根据一致性原则,要么
X+Y=1000,要么X+Y=50450
现在假设T已经执行到Read (Y),然后T’‘开始。操作是交错发生的,由于未做好事务隔离性,导致T’'读取X的是已经修改过的值但**Y的值还是默认值500,**最终事务T“计算结果: X+Y= 50000+500 = 50500 写入到Z。
由于2个事务之间未做好隔离性,导致数据出现了不一致。因此,事务必须要相互隔离,事务T完成X、Y更改并写入到主存储器,事务T“才能看到完整的更改。
持久性(Durability)
此属性确保一旦事务完成执行,对数据库的更新和修改将存储并写入磁盘。即使硬件故障或系统崩溃的情况下也不会丢失,只有数据库恢复,也能够根据事务日志将其灰度到事务成功结束的状态。
许多数据库通过引入预写式日志(Write-ahead logging,缩写 WAL)机制,来保证事务持久性和数据完整性,同时又很大程度上避免了基于事务直接刷新数据的频繁IO对性能的影响。
在使用WAL的系统中,所有的修改都先被写入到日志中,然后再被应用到系统状态中。假设一个程序在执行某些操作的过程中机器掉电了。在重新启动时,程序可能需要知道当时执行的操作是成功了还是部分成功或者是失败了。如果使用了WAL,程序就可以检查log文件,并对突然掉电时计划执行的操作内容跟实际上执行的操作内容进行比较。在这个比较的基础上,程序就可以决定是撤销已做的操作还是继续完成已做的操作,或者是保持原样。
并发事务存在问题
在许多事务同时处理一个数据的时候,如果没有采取有效的隔离机制的话,那么并发处理数据时,会带来一些问题。
脏读(读取未提交事务数据)
脏读又称无效数据的读出,是指在数据库访问中,事务 A 对一个值做修改,事务 B 读取这个值,但是由于某种原因事务 A 回滚撤销了对这个值得修改,这就导致事务 B 读取到的值是无效数据。如下图:
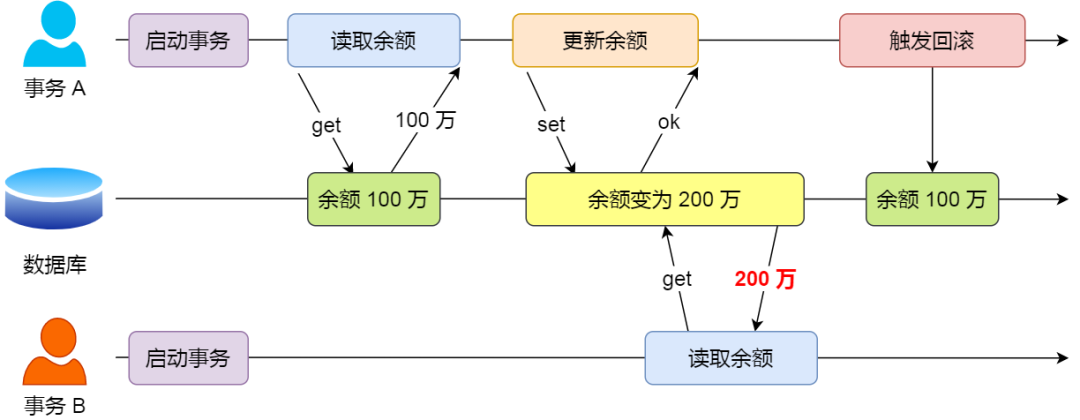
假设有 A 和 B 这两个事务同时在处理,事务 A 先开始从数据库中读取余额数据,然后再执行更新操作,如果此时事务 A 还没有提交事务,而此时正好事务 B 也从数据库中读取余额数据,那么事务 B 读取到的余额数据是刚才事务 A 更新后的数据,所以事务A就出现了脏读问题,这种情况会出现2种后果:
- 事务A继续执行事务并提交,事务B读取到正确数据
- 事务A执行过程中出现故障,选择回滚事务。但是事务B拿到的余额是修改后的,这时候事务B后续处理其他逻辑就会出现错误
事务隔离级别为读未提交(Read Uncommited)会出现脏读问题
不可重复读(前后多次读取同一数据,结果内容不一致)
不可重复读即当事务 A 按照查询条件读取数据,这时事务 B 对事务 A 查询的结果集数据做了修改操作,之后事务 A 为了数据校验继续按照之前的查询条件得到的结果集与前一次查询不同,导致不可重复读取原始数据。如下图:
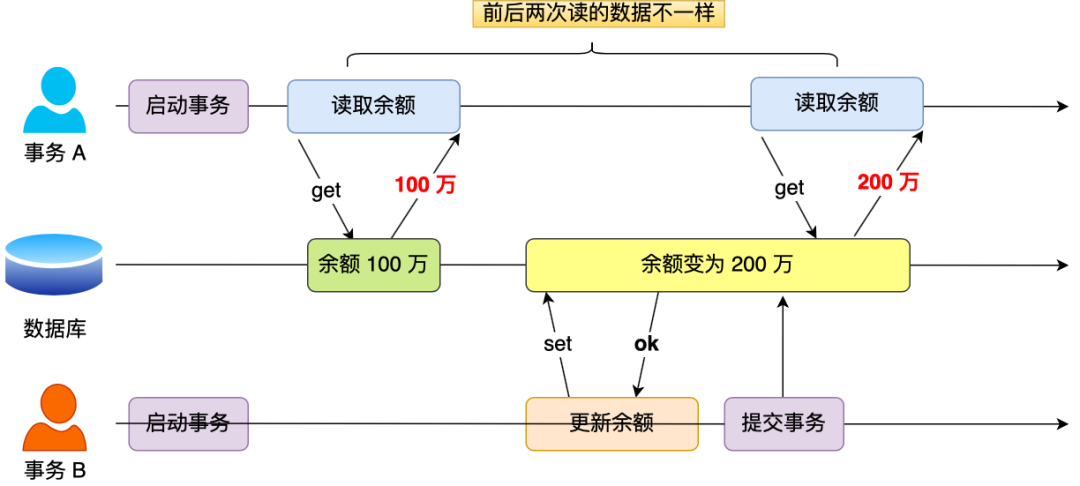
事务隔离级别为读提交(Read Committed)解决了脏读问题,但存在不可重复读问题
幻读(前后数据多次读取,结果集数量不一致)
幻读是指当事务 A 按照查询条件得到了一个结果集,这时事务 B 对事务 A 查询的结果集数据做新增或者删除操作,之后事务 A 继续按照之前的查询条件得到的结果集商品不见了,好像出现了幻觉一样。如下图:
假设有 A 和 B 这两个事务同时在处理,事务 A 先开始从数据库查询账户余额大于 100 万的记录,发现共有 5 条,然后事务 B 也按相同的搜索条件也是查询出了 5 条记录。
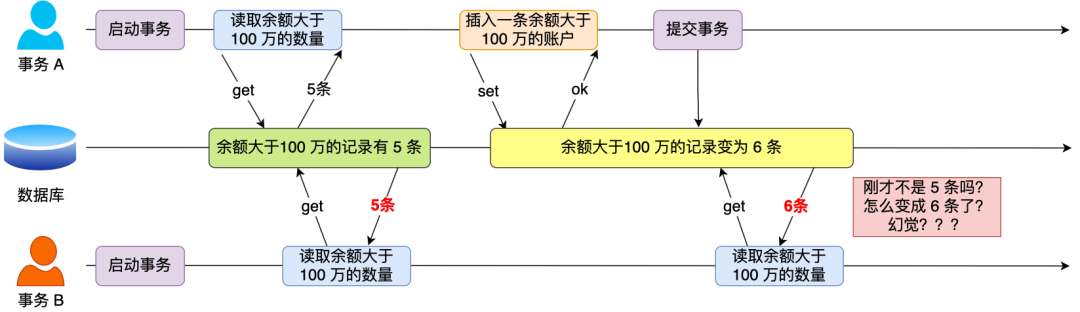
接下来,事务 A 插入了一条余额超过 100 万的账号,并提交了事务,此时数据库超过 100 万余额的账号个数就变为 6。
然后事务 B 再次查询账户余额大于 100 万的记录,此时查询到的记录数量有 6 条。
幻读和不可重复读问题都是对在一个事务内多次读取出现不一致的描述。只不过他们的侧重点不同
- 不可重复读描述的侧重点是修改操作,读取到的同一条数据内容出现不一致
- 幻读描述的侧重点是添加和删除操作,读取到的数据个数出现不一致
事务隔离级别
前面我们提到,当多个事务并发执行时可能会遇到「脏读、不可重复读、幻读」的现象,这些现象会对事务的一致性产生不同程序的影响。
- 脏读:读到其他事务未提交的数据;
- 不可重复读:前后读取的数据不一致;
- 幻读:前后读取的记录数量不一致。
这三个现象的严重性排序如下:

针对并发事务存在问题,数据库事务提供了4种隔离级别,由低到高依次为:读未提交、读提交、可重读读、可串行化。这四个级别可以逐个解决脏读、不可重复读、幻读问题
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(Read Uncommitted) | ✔️ | ✔️ | ✔️ |
| 读提交(Read committed) | ✖️ | ✔️ | ✔️ |
| 可重复读(Repeatable read) | ✖️ | ✖️ | ✔️ |
| 可串行化(Serializable) | ✖️ | ✖️ | ✖️ |
接下来让我们看下四种隔离级别定义,去理解隔离级别是如何解决并发事务的问题
读未提交(Read Uncommitted)
如果一个事务已经开始写数据但没有commit,另外一个事务则不允许同时进行写操作,但允许读此数据。
该隔离级别可以通过“排他写锁”实现。
读提交(Read Committed)
这个隔离级别比读未提交强一些,读取数据的事务能读取到其他事务已提交的数据,而不关心其他事务对该数据做修改亦或者是对数据集进行新增或删除操作。这个隔离级别不会出现脏读、但会出现不可重读、幻读问题。
该隔离级别可以通过“瞬间共享读锁”和“排他写锁”实现。
可重复读(Repeatable Read)
读取数据的事务禁止对读取的数据内容做更新的操作(也就是update操作),但不禁止新增或删除数据集操作。该隔离级别解决了不可重复读取和脏读取,但是会出现幻读问题。
该隔离级别可以通过“共享读锁”和“排他写锁”实现。
可串行化(Serializable)
提供最严格的事务隔离。所有的事务,虽然提交的时候是可以并行的,但实际执行过程中事务只能一个接着一个地执行,不能并发执行。仅仅通过“行级锁”是无法实现事务序列化的,必须通过其他机制保证新插入的数据不会被刚执行查询操作的事务访问到。
内容小结
可以看到,通过ACID理论做为指导原则,可以保证事务执行是正确可靠的。通过原子性、一致性、持久性保证单个事务执行的可靠性。但是在实际应用场景中,通常都是多个事务并发执行。多个并发事务执行会存在脏读、不可重读读、幻读等问题。这就需要我们设置事务隔离级别来解决。
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed。它能够避免脏读取,而且具有较好的并发性能。尽管它会导致不可重复读、幻读的并发问题,但是我们可以在可能出现这类问题的个别场合,通过应用程序采用悲观锁或乐观锁来解决。