分布式共识算法之Paxos
分布式系统存在问题
分布式系统中节点通信采用消息传递模型,基于此通讯模型的分布式系统,不可避免会出现故障或部分失效。如:
- 硬件存在问题(磁盘损坏、接口松动)导致出现系统性故障(如内核崩溃、系统重启或被Kill)
- 数据中心网络分区故障,出现一部分节点能正常工作,其他节点
部分失效
正式因为这种不确定性大大提高了分布式系统的复杂度,所以一个健壮的分布式系统,必须满足CAP中的P(分区容错性)同时根据系统特点选择C或者A。
为什么必须满足P(分区容错性)?
在上文说过了网络、硬件等故障在所难免。当出现故障后,不能因为一个或者几个节点导致服务不可用。在网络分区形成的独立小集群时用户访问数据仍然能提供服务,这就要求分布式必须满足分区容错性
什么情况下要保证系统C(一致性)?
我们先来说什么是一致性。一致性说的是客户端每次读操作,不管访问到哪个节点,要么读到的是同一份最新写入的数据、要么就读区失败。
拿一个银行数据库系统来说,为了分布式特性数据库设计为一主多从。当用户要存入银行账户上¥100,需要发送修改命令到主副本上然后后主副本同步给从副本。如果出现主从副本数据不一致,用户正好通过从副本查询会出现存入¥100消失了。
非重要数据选择保证系统A(可用性)
可用性既只要不是服务宕机,所有请求都可以得到正确响应,一些节点可能返回最新的信息。
什么是Paxos算法?
Paxos算法是莱斯利·兰伯特于1990年提出的一种基于消息传递且具有高度容错特性的共识算法。 需要注意的是,Paxos常被误称为“一致性算法”。但是“一致性”和“共识”并不是同一个概念。Paxos是一个共识算法。
Paxos算法如何解决CAP问题
假设我们要实现一个分布式集群,这个集群是由节点 A、B、C 组成,提供只读 KV 存储服务。现在我们创建了一个只读变量,根据上面描述CAP理论,所有节点必须要先对制度变量值达成共识,然后所有节点再一起创建这个只读变量。
首先,我们希望写入数据时,能够向一组服务写入,而不是单个服务器。当客户端要请求的这组服务器某一台挂掉了,请求者都能向里面的另一台服务器发起请求,并且请求发送完成后,最终写入到多组服务中。
其次,当有多个客户端发起请求修改同一个Key写入不同value,请求发送到服务器上。当客户端去查询这组服务器中某几台时候,查询结果都要保持一致。
先看一个案例
当有多个客户端(比如客户端 1、2)访问这个系统,试图创建同一个只读变量(比如 X),客户端 1 试图创建值为 3 的 X,客户端 2 试图创建值为 7 的 X,这样要如何达成共识,实现各节点上 X 值的一致呢?带着这个问题,我们接下来继续深入了解Paxos原理。
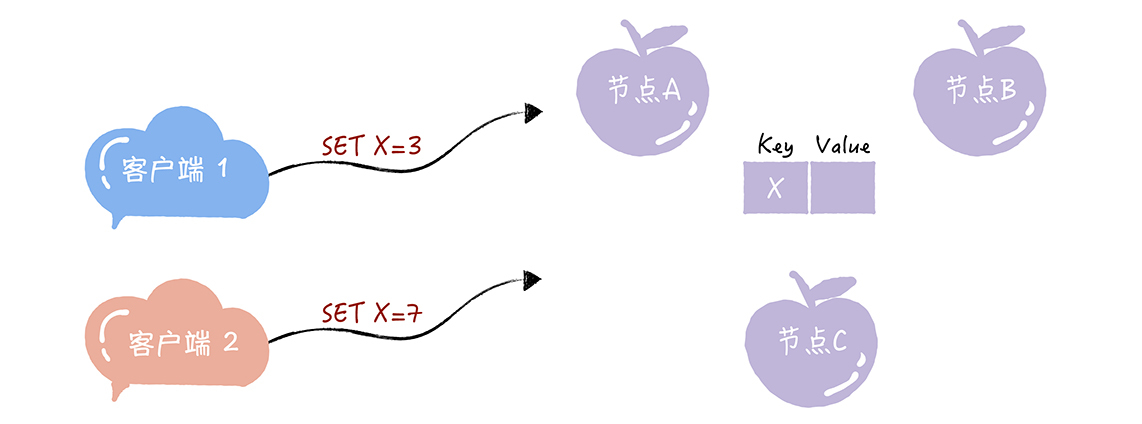
如何达成共识
在 Paxos 算法里,我们把每一个要写入的操作,称之为提案(Proposal)。接受外部请求,要尝试写入数据的服务器节点,称之为提案者(Proposer)
上图客户端1SET X=3 就是一个提案(Proposal),客户端1提交到节点A,节点A也被称为提案者(Proposer)
在Paxos算法里,并不是一个提案者接受到客户端的请求,就决定接下来操作,而是有一个异步协调的过程,在这个协调过程中,只有获得多数通过(Acceptor)的请求才会进行处理。比如节点A、B、C都在扮演接受者角色,参与共识协商,并接受和存储数据。
Paxos算法是一个两阶段提交过程,但再两阶段提交前,针对每一个请求也就是提案,我们都申请一个提案编号。
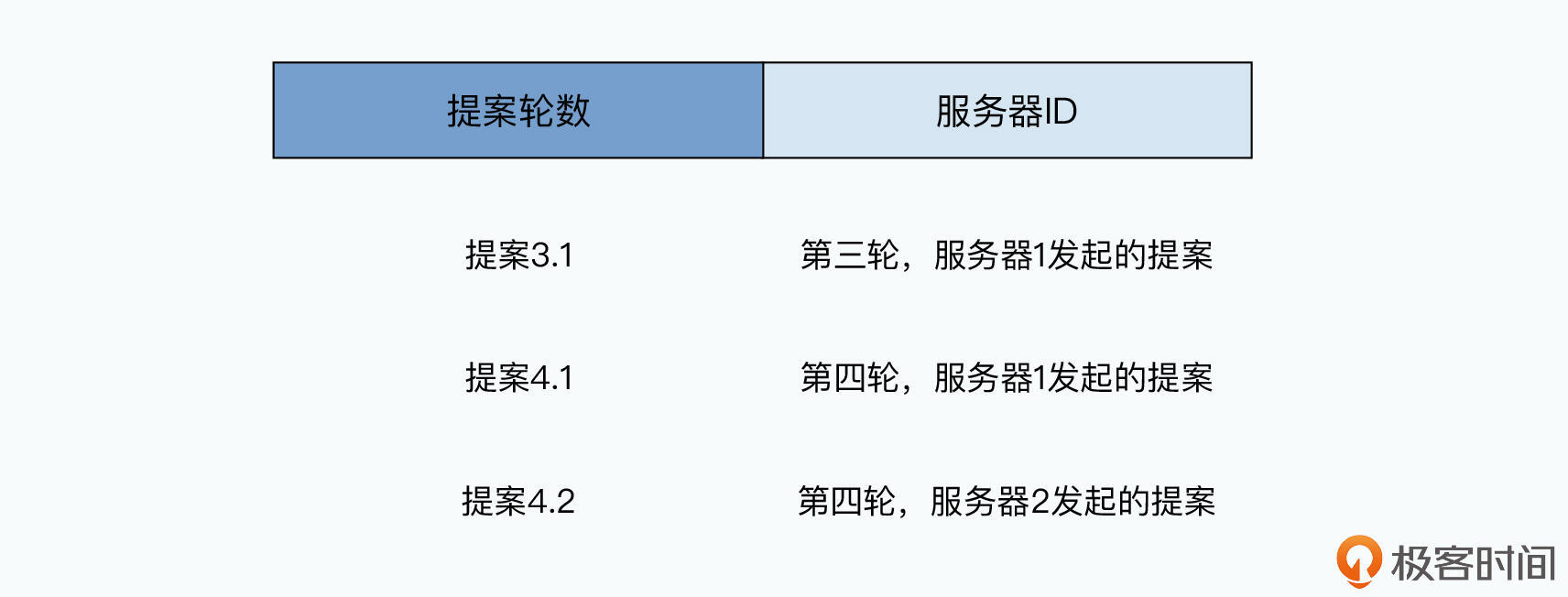
给提案编号
提案编号由两部分组成:
-
高位是整个提案过程的轮数(round)
-
低位是服务器编号,比如服务A、B、C分别编号为1、2、3
当一台服务器想发起一个新提案时候,就要用拿到的最大轮数+1,作为新提案的轮数并把服务器编号拼接上去,作为提案号发送出去
准备(Prepare)阶段
-
先来看第一个阶段,首先客户端 1、2 作为提议者(为了方便大家理解这里把客户端发起称为提议者,实际提议者由客户端请求节点发起),分别向所有接受者发送包含提案编号的准备请求:
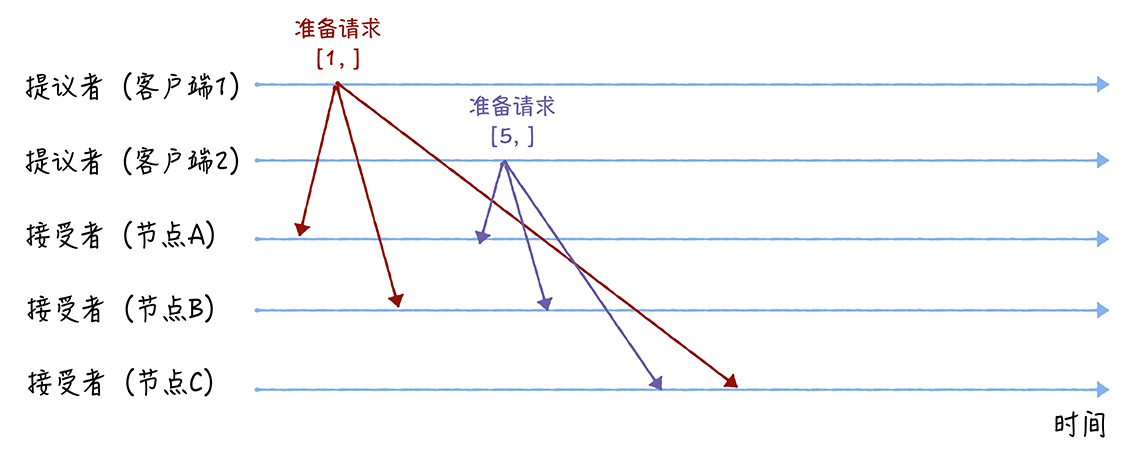
在准备阶段,提议者不需要指定提议值,只需要携带提案编号就可以
-
接着节点A、B收到提案编号1的准备请求、节点C收到提案编号5的准备请求
-
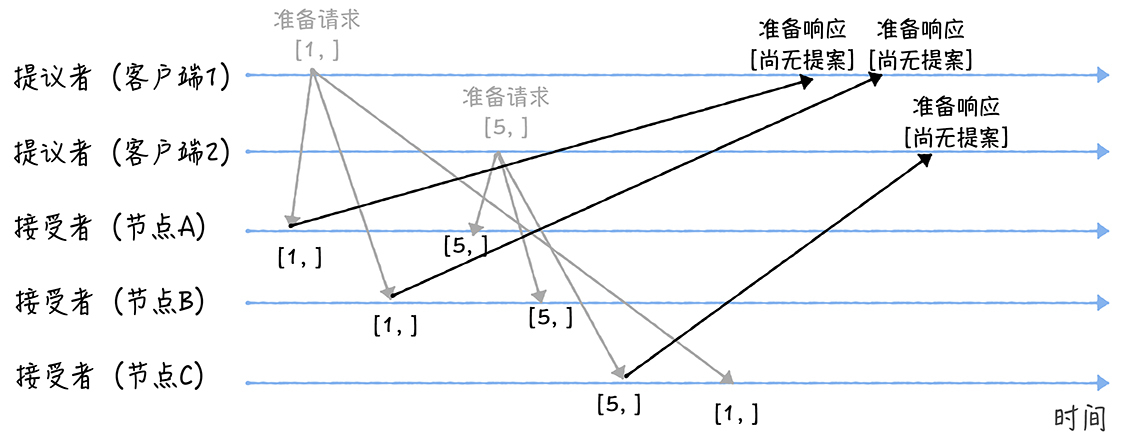
由于节点A、B、C之前都没有收到过提案,所以接受者都会承诺接受提案并返回“尚无提案(NULL)”的相应
-
当节点承诺接受提案后,永远不会再接受比当前提案号小的节点。比如:节点C以后不再响应提案编号<=5的准备请求,不会通过编号小于5的提案
-
-
接着节点A、B收到提案编号5的准备情况、节点C收到提案编号1的请求:
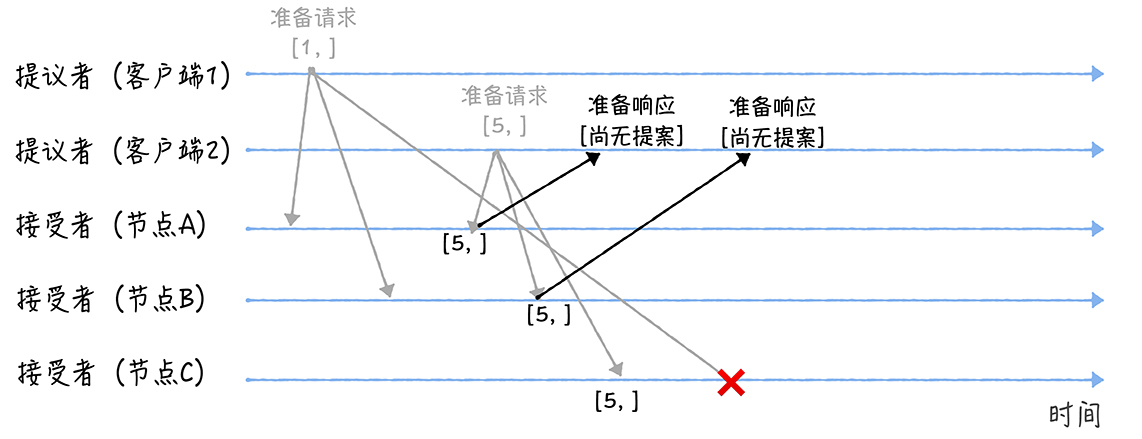
- 节点A、B收到提案编号为5的准备请求时候,由于新接受提案编号5大于之前存储的提案编号1准备请求,而且两个节点之前没有通过任何提案,所以它同样会承诺接受提案并返回“尚无提案(NULL)”的相应,同时承诺以后不再响应提案编号<=5的准备请求
- 节点C由于收到提案编号为1的准备请求时候,由于提案编号1小于它之前存储的提案编号为5的准备请求,所以它会丢弃改准备请求不做响应
接受(Accept)阶段
-
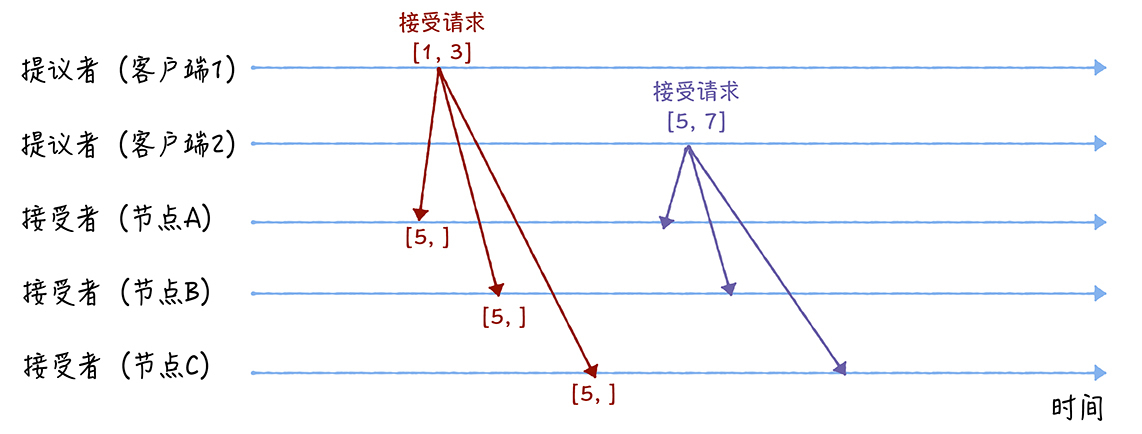
第二阶段也就是接受阶段,首先客户端1、2在接受到大多数节点的准备响应后,会分别发送接受请求
大多数节点定义:
n /2 + 1。比如3个节点要想达到大多数投票数(Quorum),通过计算需要2个节点通过。同样5个节点需要3个节点通过。这也是为什么通常会选择 3 个或者 5 个节点这样的奇数数字,因为如果是偶数的话,遇到 2:2 打平这样的事情,我们就没法做出判断了。- 由于客户端1在准备阶段收到大多数接受者(A、B)的准备响应,根据响应中提案编号1设置提案值,所以就把自己提案值3作为提案发送到接受者:[1,3]
- 由于客户端2在准备阶段收到大多数接受者(A、B、C)的准备响应,根据响应中提案编号5设置提案值,所以就把自己提案值7作为提高发送到接受者:[5, 7]
-
当三个节点收到2个客户的的接受请求时,会进行如下处理:
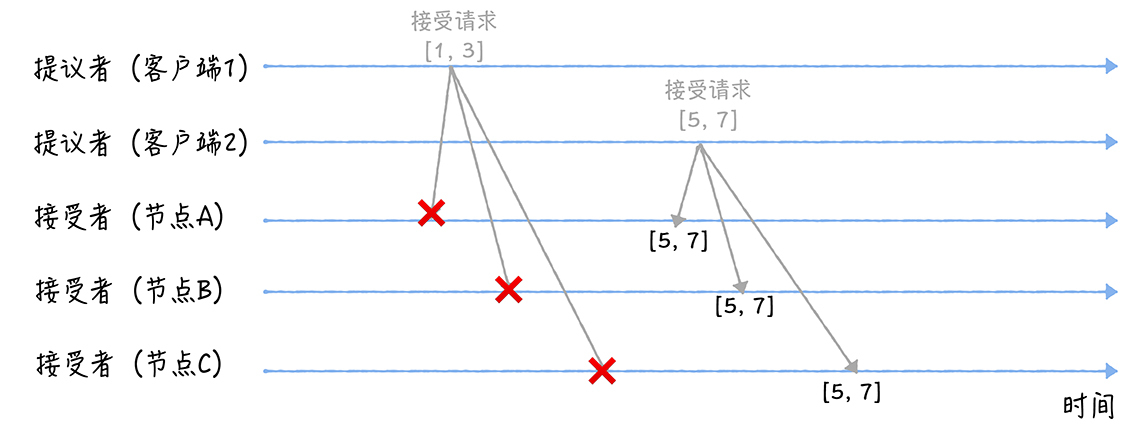
- 当接受者(A、B、C)在准备阶段承诺不再接受提案编号比5小的提案,所以提案[1, 3]将被拒绝
- 当接受者(A、B、C)收到提案编号为5的提案时。根据存储编号为5的提案,接受者只要在接受阶段接受到>=5提案编号,就给予通过,所以三个节点就达成了[5,7]的共识
内容小结
可以看到在Paxos算法过程中,所有节点需要对当前接受的哪一个提案达成共识。如果有多个提案者同时想要向一个一致性模块写入一条日志,那么最终只有有一条被成功写入,其余提案都会被放弃。多个提案通过提案编号大小去竞争一次成功提案机会。
通过Paxos算法,我们能够保证所有服务器上写入的日志的顺序是一致的,但我们并不关心某个提案者会比另一个提案者先写入。毕竟这些请求都是在网络中请求的,服务器无法决定先后顺序只能根据提案者生成的提案编号定义谁先谁后。