图解高性能网络框架Reactor
前言
在一般的可伸缩网络服务或分布式服务中,大都具备一些相同的处理流程:
- 读取请求数据
- 对请求数据进行解码
- 对请求数据进行处理
- 对回复数据进行编码
- 发送回复数据
当然在实际应用中,不同类别业务的效率都是不同的。比如:X ML解析、文件传输、Web页面加载、计算服务等
那么如何构建一个可伸缩的高性能的IO网络框架?
传统的BIO模型
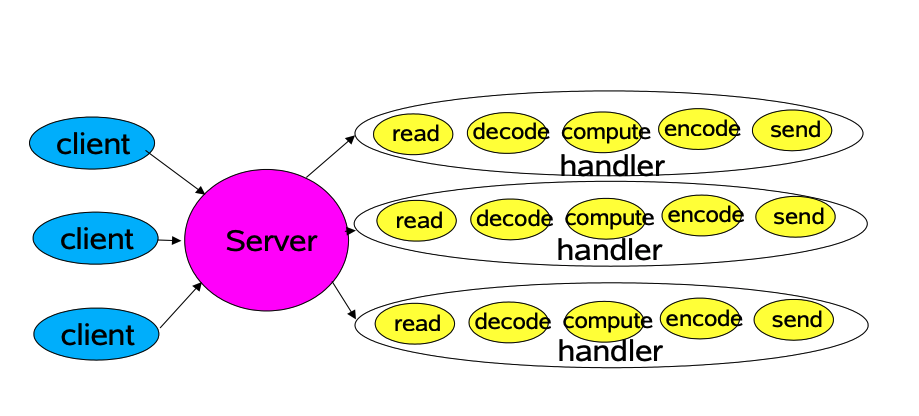
代码案例
class Server implements Runnable { public void run() { try { ServerSocket ss = new ServerSocket(PORT); while (!Thread.interrupted()) new Thread(new Handler(ss.accept())).start(); // or, single-threaded, or a thread pool } catch (IOException ex) { /* ... */ } } static class Handler implements Runnable { final Socket socket; Handler(Socket s) { socket = s; } public void run() { try { byte[] input = new byte[MAX_INPUT]; socket.getInputStream().read(input); byte[] output = process(input); socket.getOutputStream().write(output); } catch (IOException ex) { /* ... */ } } private byte[] process(byte[] cmd) { /* ... */ } } }
- 客户端向服务端发送请求后,每一个连接都会分配一个新的线程处理,该线程会包含读取数据、解码、业务处理、回复编码、发送回复
- 服务端处理完业务逻辑后,随后连接关闭线程销毁。这样线程在不停的创建和销毁,对操作系统来说每个线程创建需要给它分配内存(1M内存)、列入调度,同时线程过多会出现频繁CP U上下文切换以及内存换页等操作
- 当一个连接对应一个线程时,如果当前连接没有数据可读,那么线程会阻塞在
read操作上(socket默认情况下是阻塞I/O) - 同一时刻,服务器端的吞吐量与服务端能提供的线程数呈线性关系
基于事件驱动模式的设计
想象下,某个仿真模拟系统通过用户点击或者操作,仿真系统再执行相应指令。在架构设计中基于事件驱动的架构设计通常比传统BI O架构模型更加有效。因为可以节约一定的系统资源,避免不用为每个客户端请求创建一个线程,这意味着更少的线程开销,更少的上下文切换。
下图为java swing中基于按钮的点击事件,就是一个类似的GUI事件驱动模型
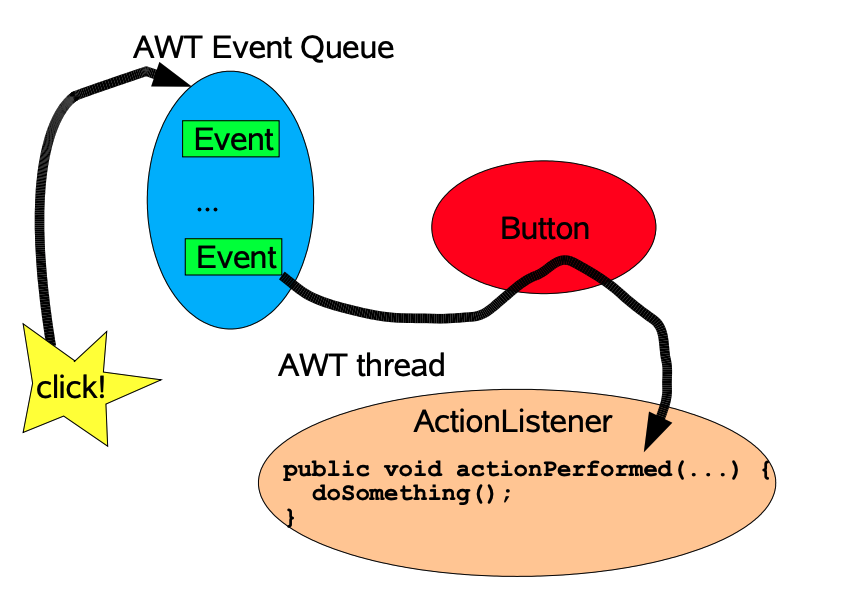
Reactor模型
要想理解事件驱动模型,先要理解select、poll、epoll等IO多路复用的机制。IO多路复用就是通过一个机制,一个进程可以监视多个文件描述符,一旦某个描述符就绪(一般是读就绪或写就绪)能通知程序进行对应读写操作。
首先,Reactor模式按中文翻译【反应堆】。为什么叫这么一个奇怪的名字,很多人按字面理解还以为是核反应堆。实际上,在Reactor模型代表是对事情驱动的反应(select、poll、epoll),也就是说来了一个事件,Reactor就有相对应的响应。
先看一个单线程模型Reactor
单Reactor单线程模式
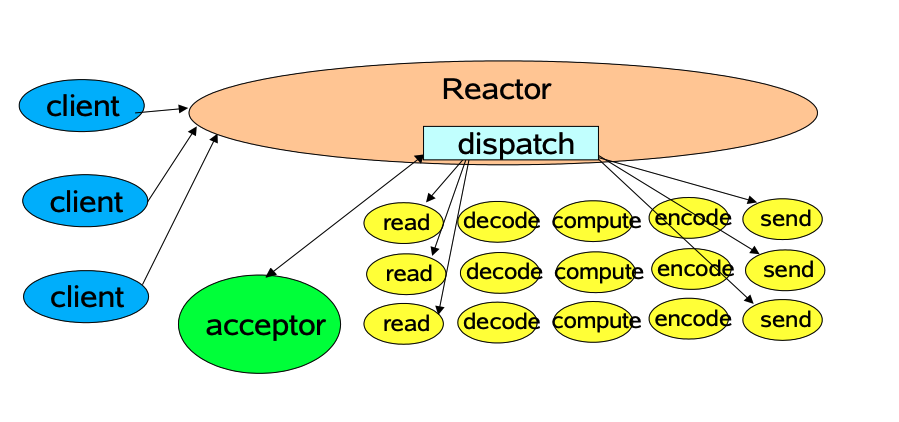
从上图可以看到Reactor主要有4个主要角色
- 客户端连接:客户端对服务器端T CP连接请求,负责传输客户端读写数据、以及建立连接通道
- Reactor:主要用来监听socket事件,收到事件后通知dispatch分发
- Acceptor: 如果是连接建立事件,由Acceptor处理。Acceptor通过调用accept接收连接,并且创建一个Handler来处理后续读写事件
- Reactor:如果不是连接建立事件,则Reactor会调用连接对应的Handler进行响应。
- Hander:处理网络服务read、decode、compute、encode、send
可以通过Java NIO相关代码具体掌握Reactor模式特性,首先我们明确下java.nio中相关的几个概念:
Channels
支持非阻塞读写的socket连接;
Buffers
用于被Channels读写的字节数组对象
Selectors
用于判断channle发生IO事件的选择器
SelectionKeys
负责IO事件的状态与绑定
Ok,接下来我们一步步看下基于Reactor模式的服务端设计代码示例:
第一步: Rector线程的初始化
class Reactor implements Runnable { final Selector selector; final ServerSocketChannel serverSocket; Reactor(int port) throws IOException { selector = Selector.open(); serverSocket = ServerSocketChannel.open(); serverSocket.socket().bind( new InetSocketAddress(port)); serverSocket.configureBlocking(false); SelectionKey sk = serverSocket.register(selector, SelectionKey.OP_ACCEPT); // 注册网络接受事件 sk.attach(new Acceptor()); // 为服务端Channel绑定一个Acceptor } public void run() { // normally in a new try { while (!Thread.interrupted()) { selector.select(); Set selected = selector.selectedKeys(); Iterator it = selected.iterator(); while (it.hasNext()) dispatch((SelectionKey)(it.next()); selected.clear(); } } catch (IOException ex) { /* ... */ } } void dispatch(SelectionKey k) { Runnable r = (Runnable)(k.attachment()); // SelectionKey绑定调用对象:Handler if (r != null) r.run(); } }第二步 定义Acceptor逻辑
class Acceptor implements Runnable { private final ServerSocketChannel serverSocket; public Acceptor(ServerSocketChannel serverSocket) { this.serverSocket = serverSocket; } public void run() { try { SocketChannel c = serverSocket.accept(); if (c != null) new Handler(selector, c); } catch(IOException ex) { /* ... */ } } }第三步 Handler处理类的初始化
final class Handler implements Runnable { final SocketChannel socket; final SelectionKey sk; ByteBuffer input = ByteBuffer.allocate(MAXIN); ByteBuffer output = ByteBuffer.allocate(MAXOUT); static final int READING = 0, SENDING = 1; int state = READING; Handler(Selector sel, SocketChannel c) throws IOException { socket = c; c.configureBlocking(false); // Optionally try first read now sk = socket.register(sel, 0); sk.attach(this); //将Handler绑定到SelectionKey上 sk.interestOps(SelectionKey.OP_READ); sel.wakeup(); } boolean inputIsComplete() { /* ... */ } boolean outputIsComplete() { /* ... */ } void process() { /* ... */ } public void run() { try { if (state == READING) read(); else if (state == SENDING) send(); } catch (IOException ex) { /* ... */ } } void read() throws IOException { socket.read(input); if (inputIsComplete()) { process(); state = SENDING; // Normally also do first write now sk.interestOps(SelectionKey.OP_WRITE); } } void send() throws IOException { socket.write(output); if (outputIsComplete()) sk.cancel(); } }
了解Reactor模型角色定义,我们再来看单线程模型这个方案优缺点:
优点
- 消息的读写、处理全部工作在同一个Handler,实现起来比较简单
缺点
- Handler在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈
- 只有一个线程,无法充分利用多核CPU的性能
所以,单Reactor单线程模式不适合计算机密集型的场景,只使用于业务处理非常快速创建
单Reactor多线程模式
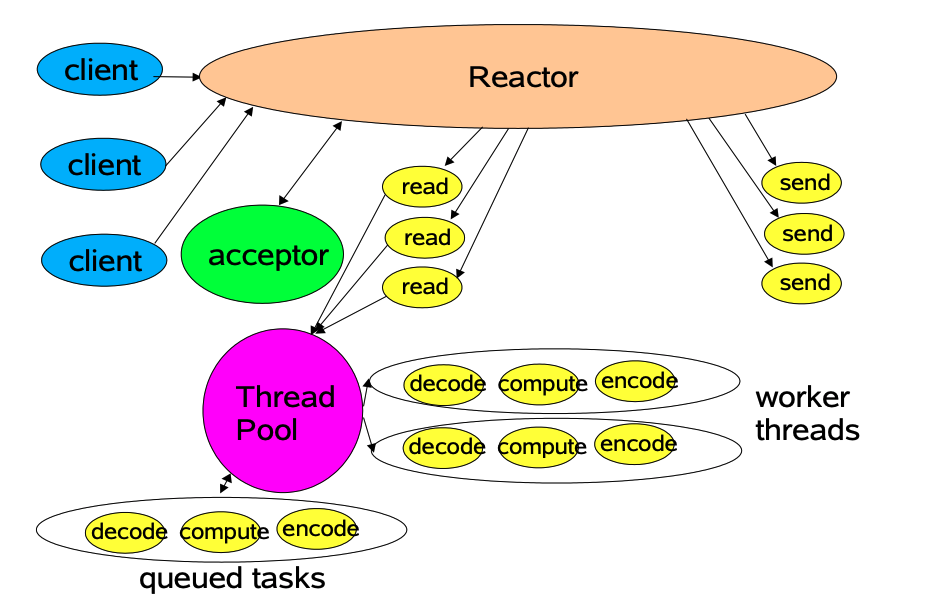
在多处理器场景下,为了实现服务的高性能我们可以有目的采用多线程模式:
- 增加Worker线程,专门处理非IO操作。因为通过上面JAVA程序我们可以看到,
Handler类中process方法处理业务过程。通常业务处理会涉及到大量复杂逻辑,比如数据库操作、程序计算等,会导致Handler会出现阻塞导致性能瓶颈 - 新增worker线程池后
Handler对象不再负责业务处理、只负责数据的read/write。handler对象通过read读到数据后,会从worker线程池中申请一个线程进行业务处理 - worker线程处理完后,会将结果发给主线程中的
handler对象,接着由Handler通过send方法将响应结果发送给client
相应JAVA代码改造如下:
class Handler implements Runnable { // uses util.concurrent thread pool static PooledExecutor pool = new PooledExecutor(...);//声明线程池 static final int PROCESSING = 3; // ... synchronized void read() { // ... socket.read(input); if (inputIsComplete()) { state = PROCESSING; pool.execute(new Processer());//处理程序放在线程池中执行 } } synchronized void processAndHandOff() { process(); state = SENDING; // or rebind attachment sk.interest(SelectionKey.OP_WRITE); } class Processer implements Runnable { public void run() { processAndHandOff(); } } }
这种模式相比前面单线程模式再性能上有很大提升,主要在网络读写的同时,也可以进行业务计算,从而大大提高类系统吞吐量。但这种模式也存在不足,主要:
- 网络读写也是一个比较消耗CPU的操作。在高并发场景下,会有大量的客户端数据需要进行网络读写
- 一个Reactor对象承担所有事件监听以及网络读写。那么单Reactor将成为整个模型瓶颈
多Reactor多线程模式
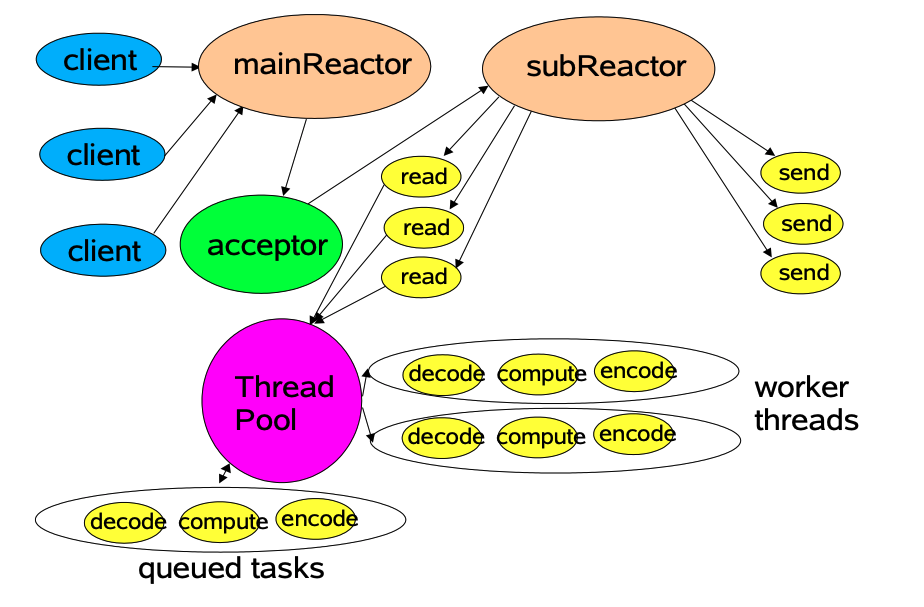
方案如下:
- 主线程
mainReactor对象通过基于事件驱动方式监控连接,收到事件后Acceptor对象中的accpet获取连接,将新的已建立连接socket分配subReactor子线程 - 子线程中的
subReactor将mainReactor对象分配的连接加入selector进行继续监听,并创建一个Handler处理连接的响应事件 - 如果有新的事件发生时,
subReactor对象会调用当前连接对应的Handler对象来进行响应。 Handler对象通过read -> 业务处理 -> send的流程来完成完整的业务流程。
tips: Selector集合,每一个Selector 对应一个subReactor线程
Selector[] selectors; // Selector集合,每一个Selector 对应一个subReactor线程 //mainReactor线程 class Acceptor { // ... public synchronized void run() { //... Socket connection = serverSocket.accept(); if (connection != null) new Handler(selectors[next], connection); if (++next == selectors.length) next = 0; } }
多 Reactor 多线程的方案虽然看起来复杂的,但是实际实现时比单 Reactor 多线程的方案要简单的多,原因如下:
- 主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成后续的业务处理。
- 主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客户端。
内容小结
通过对传统网络BIO模型以及Reactor网络模型学习,我们了解到:
- BIO为同步阻塞IO。针对每个连接需要创建一个线程处理连接、网络读写等。这种模型比较适合只需要支持少量连接的场景
- Reactor作为同步非阻塞IO。多Reactor多线程模式下
mainReactor与subReactor分工明确,主线程负责接受新的连接,子线程负责完成后续网络读写,worker线程负责处理业务计算。更适合在多处理场景下支持高并发、大量在线活跃连接业务。