服务治理三板斧之限流
什么是限流
在日常生活中,有各种各样的限流举措。比如在拥堵或者交通管制的城市中,当汽车保有量达到道路容量的极限时,就会实施车辆通行限制措施。以北京为例就采用车牌尾号限行、潮汐道限行、公交车道限行、特定区域限行等措施来控制车辆通行。
回到主题,在软件工程领域中限流和日常生活中的限流有着很多相似之处。它们的目的都是为了避免系统或者资源出现过载、崩溃、浪费等问题,确保系统在承受范围内提供稳定的服务。
为什么要限流?
限流的目的是为了保护系统的稳定性和资源的公平利用。以下是一些常见的限流原因:
- 保护后端服务:当系统面临突发的高并发流量,后端服务的处理能力是有限的。如果没有限流措施,系统可能会因为超负荷而崩溃或响应变慢,影响正常的业务流程。通过限制每秒或每分钟的请求量,可以确保后端服务能够稳定运行,提高系统的可用性。
- 保护关键资源:有些系统资源是有限的,例如数据库连接、线程池、内存等。如果不进行限流,某些请求可能会长时间占用关键资源,导致其他请求无法得到响应。通过限流,可以确保资源被合理分配和利用,避免因个别请求的占用而影响整体系统性能。
- 公平分配资源:对于提供公共服务的第三方开发平台,限流也是为了公平分配资源。如果某个接口没有限流,某些用户可能会过度使用资源,导致其他用户无法正常访问。通过限制每个用户的请求量,可以确保资源被公平地分配给所有用户。
- 防止雪崩效应:当系统的某个依赖服务出现故障或延迟时,如果没有限流措施,系统可能会出现级联故障,导致整个系统崩溃。通过限流,可以减缓流量的涌入,降低对故障服务的依赖,从而避免雪崩效应的发生。
- 防止恶意行为:有些不正常的流量可能是恶意的,例如爬虫攻击、DDoS 攻击等。通过限制请求的频率或总量,可以减少对系统的恶意攻击和滥用,保护系统的安全性。
- 保护用户体验:在高并发情况下,如果系统没有限流,响应时间可能会变得很慢,用户可能会遇到长时间的等待或超时问题,降低用户体验。通过限制并发请求数量或响应时间,可以确保用户获得较快的响应,提升用户体验和满意度。
- 控制数据一致性:在某些分布式系统中,为了保证数据的一致性,可能需要对数据更新的并发操作进行限流。通过限制同时进行的写操作数量,可以避免数据冲突和不一致的问题。
- 控制成本和资源利用率:限流可以避免资源过度消耗和不必要的成本。在一些商业场景下,可能需要对服务进行计费或资源按需付费,通过限流可以控制资源使用量,避免不必要的费用支出。
- 节约带宽和资源消耗:在一些网络通信场景下,限流可以帮助节约带宽和资源消耗。例如,对于实时视频流或大文件下载,通过限制带宽使用量,可以避免网络拥堵和过度资源消耗。
总的来说,限流在软件工程中扮演着重要的角色,它不仅可以保护后端服务、防止恶意行为,还可以保护关键资源、公平分配资源,控制成本和资源利用率,防止雪崩效应,保护用户体验,控制数据一致性,以及节约带宽和资源消耗。这些原因都体现了限流在保障系统稳定性、安全性和性能方面的重要作用。
常见限流算法
通常限流采用对请求的频次、并发的连接、消息队列处理速率、API调用等策略来防止突发流量高峰冲击系统。这些策略采用一些限流算法实现。
计数限流
计数限流基于对请求进行计数来控制系统流量。当收到一个请求时,计数器会递增,如果计数器超过了限制的最大请求数,那么该请求可能会被拒绝。
计数限流可以根据应用的部署方式分为单机计数限流和集群计数限流两种形式:
-
单机计数限流:在单机计数限流中,限流的计数器仅存在于单个服务实例中。该实例记录并管理请求计数,用于控制该实例接收的请求流量。这种方式适用于单机部署的应用,对于单个服务实例来说,可以对请求进行计数和限制。
public class CountLimiter { private final int maxRequests; // 最大请求数量 private final AtomicInteger requestCount; // 请求计数器 public CountLimiter(int maxRequests) { this.maxRequests = maxRequests; this.requestCount = new AtomicInteger(0); } public boolean allowRequest() { int count = requestCount.incrementAndGet(); if (count <= maxRequests) { return true; // 允许请求 } else { requestCount.decrementAndGet(); return false; // 请求超过限制 } } public void releaseRequest() { requestCount.decrementAndGet(); } public static void main(String[] args) throws InterruptedException { CountLimiter limiter = new CountLimiter(3000); // 模拟并发请求 for (int i = 0; i < 5000; i++) { Thread thread = new Thread(() -> { boolean allowed = limiter.allowRequest(); if (allowed) { System.out.println("请求被允许"); try { Thread.sleep(1000); // 模拟请求处理时间 } catch (InterruptedException e) { e.printStackTrace(); } finally { limiter.releaseRequest(); } } else { System.out.println("请求被限流"); } }); thread.start(); } } }在这个示例代码中,
CountLimiter类表示计数限流器,通过设置最大请求数量来进行限流。allowRequest()方法用于尝试获取信号量,如果成功获取到信号量,则表示请求被允许通过;如果获取不到信号量,则表示请求被限流。在请求处理结束时,需要调用releaseRequest()方法释放信号量。示例中的
main()方法模拟了并发请求的场景。在每个线程中,首先调用allowRequest()方法尝试获取信号量,如果成功获取到信号量,则输出"请求被允许",然后模拟请求处理时间(这里使用Thread.sleep()方法表示),最后调用releaseRequest()方法释放信号量。如果获取不到信号量,则输出"请求被限流"。这种计数限流方式使用信号量来控制并发请求数量,超过最大请求数量时会被限流。这种方式不需要时间窗口,适用于实时计数限流的场景。请注意,在实际应用中,可能需要根据具体需求进行线程安全性处理和更多的优化。
-
集群计数限流:在集群计数限流中,限流的计数器在整个集群中共享和管理。集群中的不同服务实例共享请求计数,以协同控制整个集群的请求流量。通过集群级别的计数器,可以实现更精确的限流控制,并确保集群中的所有实例都遵守相同的限制。
public class CountLimiter { private final int maxRequests; // 最大请求数量 private final String redisKey = "request_count"; // Redis 键名 private final Jedis jedis; public CountLimiter(int maxRequests) { this.maxRequests = maxRequests; this.jedis = new Jedis("localhost"); // 假设 Redis 服务器在本地 } public boolean allowRequest() { long count = jedis.incr(redisKey); if (count <= maxRequests) { return true; // 允许请求 } else { jedis.decr(redisKey); return false; // 请求超过限制 } } public void releaseRequest() { jedis.decr(redisKey); } public static void main(String[] args) throws InterruptedException { CountLimiter limiter = new CountLimiter(3000); // 模拟并发请求 for (int i = 0; i < 5000; i++) { Thread thread = new Thread(() -> { boolean allowed = limiter.allowRequest(); if (allowed) { System.out.println("请求被允许"); try { Thread.sleep(1000); // 模拟请求处理时间 } catch (InterruptedException e) { e.printStackTrace(); } finally { limiter.releaseRequest(); } } else { System.out.println("请求被限流"); } }); thread.start(); } } }集群计数限流通常需要一种分布式的计数器实现,以确保计数的准确性和一致性。常见的做法是使用分布式缓存(如Redis)或分布式数据库(如ZooKeeper)来存储和共享计数器的值。集群计数限流可以实现更好的水平扩展性和容错性,适用于分布式和高可用性的应用场景。
可见,计数限流是一种非常简单粗暴的策略。相应也会带来一定问题:计数限流仅考虑请求数量,而不考虑请求的处理时间。如果短时间内出现大量的请求并且请求的处理时间很长,计数限流可能无法有效地控制系统负载,导致系统响应变慢或崩溃
固定窗口计数限流
固定窗口计数限流是在计数限流的基础上引入时间窗口的概念。将时间分割成固定长度的窗口,在每个窗口内限制请求的数量,在每个窗口内,请求数量不能超过预设的最大请求数量。它的规则如下:
- 请求次数小于阈值,允许访问并且计数器 +1;
- 请求次数大于阈值,拒绝访问;
- 这个时间窗口过了之后,计数器清零;
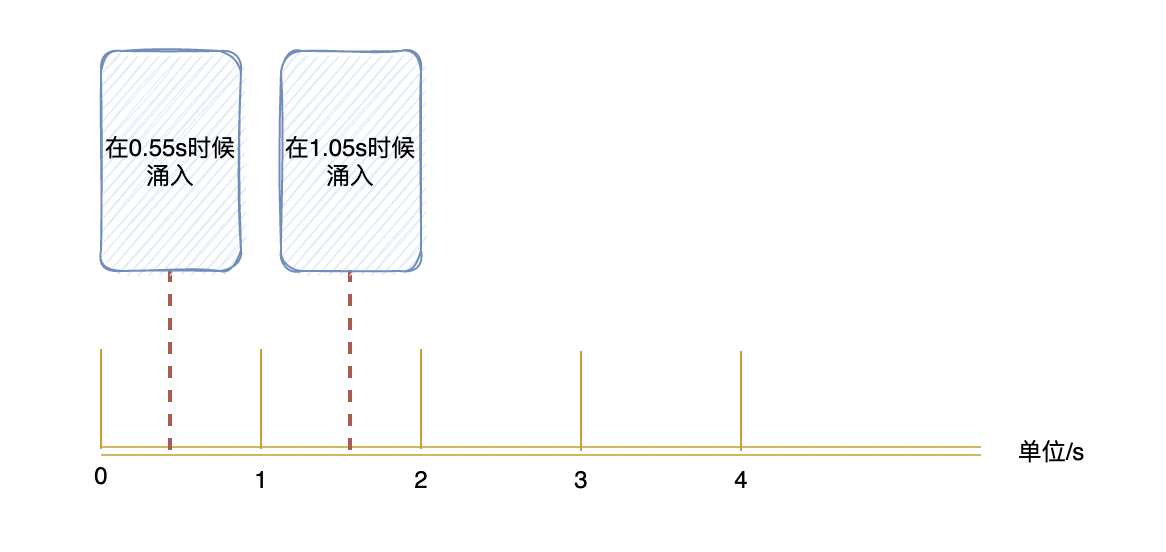
假设系统每秒允许 100 个请求,假设第一个时间窗口是 0-1s,在第 0.55s 处一下次涌入 100 个请求,过了 1 秒的时间窗口后计数清零,此时在 1.05 s 的时候又一下次涌入 100 个请求。
虽然窗口内的计数没超过阈值,但是全局来看在 0.55s-1.05s 这 0.5 秒内涌入了 200 个请求,这其实对于阈值是 100/s 的系统来说是无法接受的。
简单用例代码如下:
public class FixedWindowRateLimiter {
private final int maxRequests; // 最大请求数量
private final long windowDuration; // 时间窗口长度(单位:毫秒)
private final AtomicInteger requestCount; // 请求计数器
private long windowStart; // 时间窗口起始时间
public FixedWindowRateLimiter(int maxRequests, long windowDuration) {
this.maxRequests = maxRequests;
this.windowDuration = windowDuration;
this.requestCount = new AtomicInteger(0);
this.windowStart = System.currentTimeMillis();
}
public boolean allowRequest() {
// 获取当前时间
long currentTime = System.currentTimeMillis();
// 如果当前时间已超过时间窗口的结束时间,则重置计数器和时间窗口起始时间
if (currentTime >= windowStart + windowDuration) {
requestCount.set(0);
windowStart = currentTime;
}
// 检查请求计数是否超过最大请求数量
if (requestCount.incrementAndGet() <= maxRequests) {
return true; // 允许请求
} else {
return false; // 请求超过限制
}
}
public static void main(String[] args) throws InterruptedException {
// 创建一个允许每秒最多3个请求的计数限流器
FixedWindowRateLimiter limiter = new FixedWindowRateLimiter(3, TimeUnit.SECONDS.toMillis(1));
// 模拟一段时间内的请求
for (int i = 0; i < 10; i++) {
boolean allowed = limiter.allowRequest();
if (allowed) {
System.out.println("请求被允许");
} else {
System.out.println("请求被限流");
}
Thread.sleep(150); // 模拟请求间隔时间
}
}
}
固定窗口计数限流可以更好地控制请求的频率,避免短时间内的请求突发情况。看起来比计数限流更完美,但实际上还是有缺陷的,对于突发流量和短时间内的高峰期可能不够灵活。
滑动窗口计数限流
滑动窗口计数限流在固定窗口的基础上引入了窗口的滑动,将一定时间范围内的请求计数,与设定的阈值进行比较来判断是否限流。窗口会随着时间滑动,过期的请求计数会被移除,新的请求计数会被添加。它的规则如下:
- 窗口长度固定,表示一段时间内的时间跨度,例如1秒、1分钟等。
- 窗口之间存在重叠,每个窗口的滑动步长可以自定义,例如0.5秒、10秒等。
- 每个窗口内都有一个计数器用于统计请求的数量。
- 当窗口内的请求数量达到限流阈值时,后续请求将被限制。
- 窗口滑动时,旧窗口的计数器被清零,新窗口开始计数。
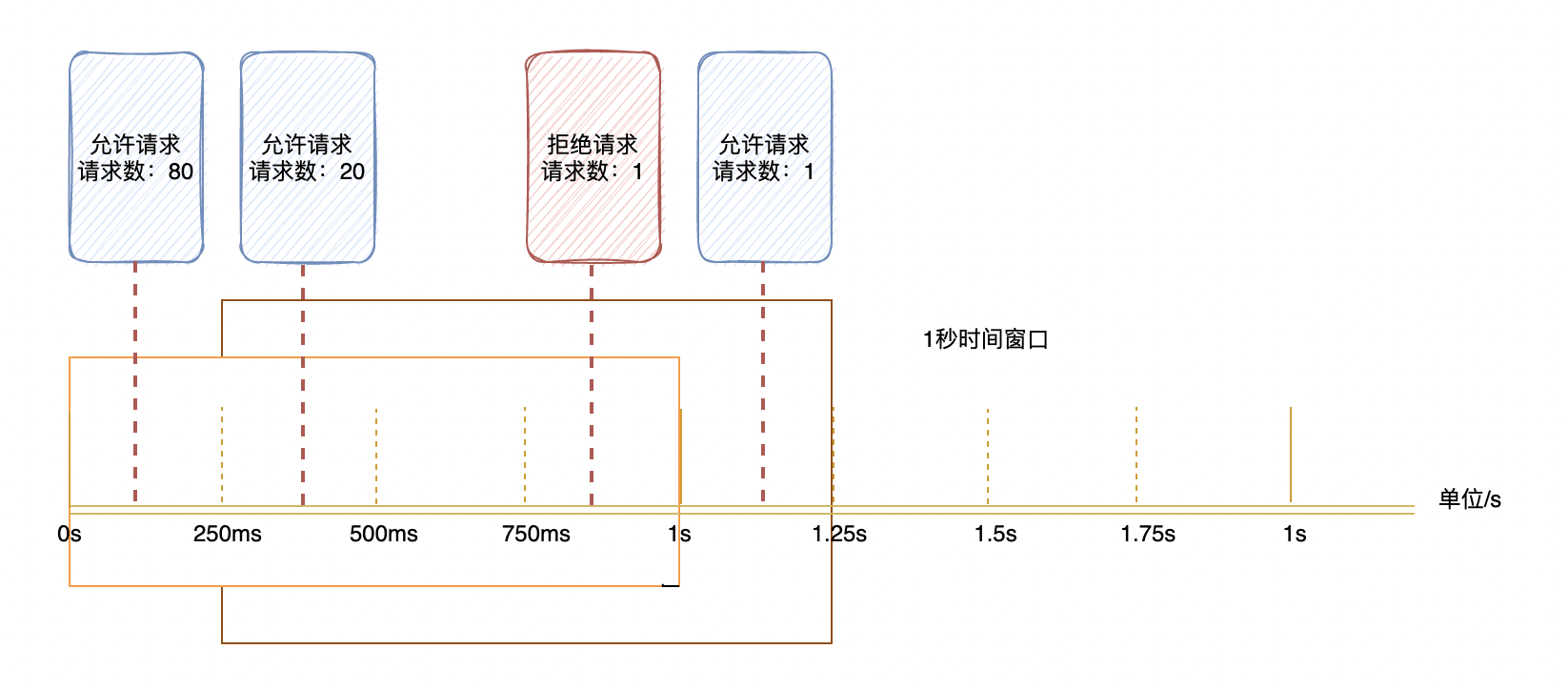
假设最大限流请求量为100,窗口长度为1s。现在分成4个bucket,也是每个bucket是250ms间隔。
假如750ms~1s之间,来了一个请求,统计当前bucket和前面三个bucket中的请求量总和101,大于阈值,就会把当前这个请求进行限流。
假如1s1.25s之间,来了一个请求,统计当前bucket和前面三个bucket中的请求量总和21,小于阈值,就会正常放行。这里请求总量统计去掉了0250ms之间的bucket,就是体现了时间窗口的滑动。
如下图,2个滑动窗口:0s~1s, 250ms~1.25s
相关用例代码如下:
public class SlidingWindowRateLimiter {
private final int maxRequests; // 最大限流请求数量
private final int windowSize; // 窗口长度,单位为毫秒
private final int slideInterval; // 窗口滑动间隔,单位为毫秒
private final LinkedBlockingDeque<SlidingWindow> window; // 滑动窗口队列,存储每个窗口的时间戳
public SlidingWindowRateLimiter(int maxRequests, int windowSize, int slideInterval) {
this.maxRequests = maxRequests;
this.windowSize = windowSize;
this.slideInterval = slideInterval;
this.window = new LinkedBlockingDeque<>(windowSize / slideInterval);
}
public synchronized boolean allowRequest() {
long currentTime = System.currentTimeMillis(); // 当前时间戳,单位为毫秒
// 清理过期的窗口
cleanExpiredWindows(currentTime);
// 如果当前窗口内请求数量达到限流阈值,拒绝请求
if (getCurRequests() >= maxRequests) {
return false;
}
// 将当前请求加入当前窗口
window.getLast().getCount().incrementAndGet();
return true;
}
private int getCurRequests() {
return window.stream().mapToInt(mapper -> mapper.getCount().get()).sum();
}
private void cleanExpiredWindows(long currentTime) {
if (window.isEmpty()) {
// 如果窗口为空,则创建一个新的窗口
window.addLast(new SlidingWindow(currentTime, 0, new AtomicInteger(0)));
} else {
// 如果窗口不为空,且窗口队列的第一个元素已经过期,则移除过期窗口
while (!window.isEmpty() && window.peekFirst().getTime() + windowSize < currentTime) {
// 移除过期窗口
window.pollFirst();
}
if (window.size() < windowSize / slideInterval) {
// 如果窗口队列的最后一个元素已经滑动到下一个窗口,则创建一个新的窗口
SlidingWindow lastWindow = window.getLast();
long nextSlidingTime = lastWindow.getTime() + slideInterval;
if (nextSlidingTime < currentTime) {
window.addLast(new SlidingWindow(nextSlidingTime,
lastWindow.getStep() + slideInterval, new AtomicInteger(0)));
}
}
}
}
@Data
private final class SlidingWindow {
// 窗口开始时间
private long time;
// 当前步长
private int step;
// 计数器
private AtomicInteger count;
// 构造器
public SlidingWindow(long time, int step, AtomicInteger count) {
this.time = time;
this.step = step;
this.count = count;
}
// 重写toString方法
@Override
public String toString() {
return "SlidingWindow{" +
"time=" + time +
", step=" + step +
", count=" + count +
'}';
}
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
SlidingWindowRateLimiter rateLimiter = new SlidingWindowRateLimiter(
100, 1000, 250);
// 模拟请求处理时间
Thread.sleep(1000);
// 模拟窗口滑动
IntStream.range(0, 80).parallel().forEach(i -> {
if (!rateLimiter.allowRequest()) {
System.out.println("限流请求 " + (i + 1));
}
}
);
// 模拟请求处理时间
Thread.sleep(250);
// 模拟窗口滑动
IntStream.range(0, 20).parallel().forEach(i -> {
if (!rateLimiter.allowRequest()) {
System.out.println("限流请求 " + (i + 1));
}
}
);
// 模拟请求处理时间
Thread.sleep(500);
if (!rateLimiter.allowRequest()) {
System.out.println("间隔时间:" + (System.currentTimeMillis() - start) + ",限流请求 " + rateLimiter.getCurRequests());
}
// 模拟请求处理时间
Thread.sleep(250);
if (rateLimiter.allowRequest()) {
System.out.println("间隔时间:" + (System.currentTimeMillis() - start) + ",允许请求 " + rateLimiter.getCurRequests());
}
}
}
虽然,滑动窗口计数限流可以更灵活地适应流量的变化。由于窗口之间存在重叠,突发流量可以被较快地响应,同时窗口的滑动也使得计数器能够及时清零,保持限流的准确性。但是在实际应用中可能存在一定的精确度问题。由于窗口的滑动间隔和长度是固定的,无法实现对请求发生时间的精确控制。某些情况下,可能会出现窗口内请求数量超过限流阈值,或者在窗口切换的瞬间出现请求被通过的情况。
那么如何解决时间窗口累的痛点,使流量更加的平滑呢,接下来然我们看看漏桶及令牌桶算法。
漏桶算法
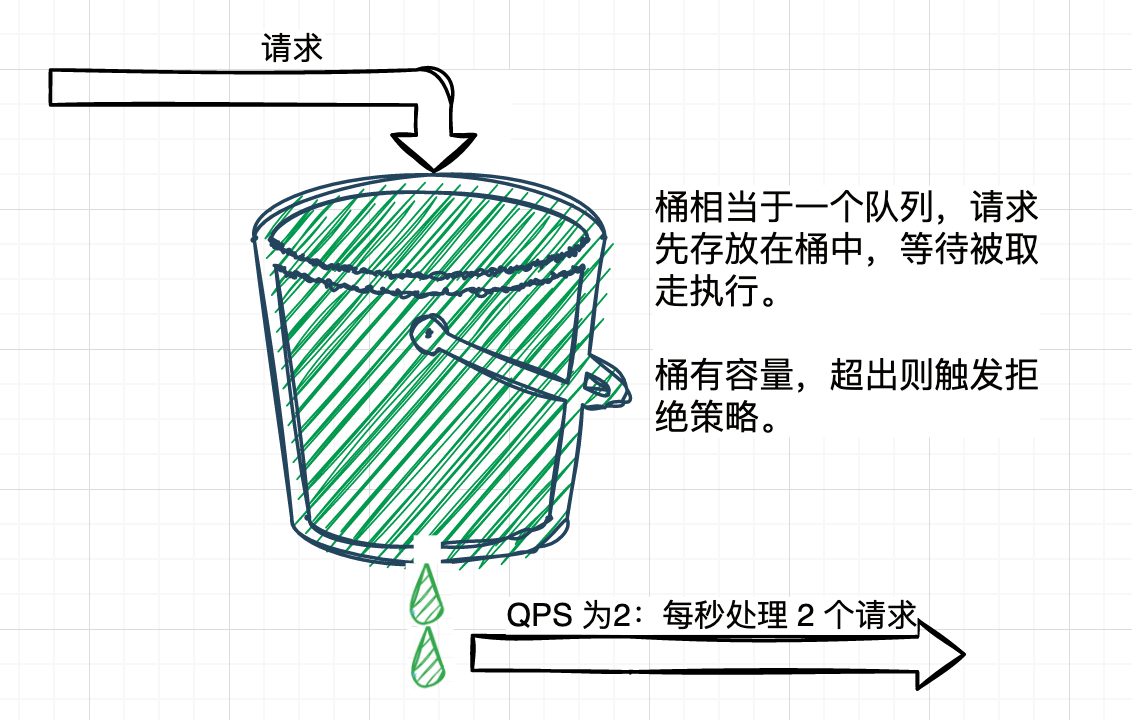
漏桶算法(Leaky Bucket Algorithm)是一种常见的流量控制算法,用于平滑请求的发送速率。它的工作原理类似于一个漏桶,请求会按照一定的速率添加到漏桶中,如果漏桶已满,则超出漏桶容量的请求会被丢弃或者排队等待处理。
漏桶算法的主要特点是它以恒定的速率处理请求。无论请求的到达速率是多快,漏桶算法都会以固定的速率将请求发送出去,从而平滑了请求的流量。
当请求到达时,漏桶会尝试将请求放入漏桶中,如果漏桶还有剩余容量,则接受请求并发送出去,同时漏桶的容量减少。如果漏桶已满,则超出容量的请求会被丢弃或者排队等待处理。
下面是漏桶算法的示意图:
相关代码实现:
public class LeakyBucket {
private final int capacity; // 漏桶容量
private final int rate; // 漏桶流出速率,单位:请求数/秒
private int water; // 桶中的水量
private long lastRequestTime; // 上一次漏水的时间戳
public LeakyBucket(int capacity, int rate) {
this.capacity = capacity;
this.rate = rate;
this.water = 0;
this.lastRequestTime = System.currentTimeMillis();
}
public synchronized boolean tryAcquire(int n) {
long currentTime = System.currentTimeMillis();
long timeElapsed = currentTime - lastRequestTime;
// 计算漏桶中的水量
water = Math.max(0, water - (int) (timeElapsed * rate / 1000));
// 更新上次请求时间
lastRequestTime = currentTime;
// 如果漏桶已满,拒绝请求
if (water + n <= capacity) {
// 处理请求,增加水量
water += n;
return true;
} else {
return false;
}
}
}
令牌桶算法
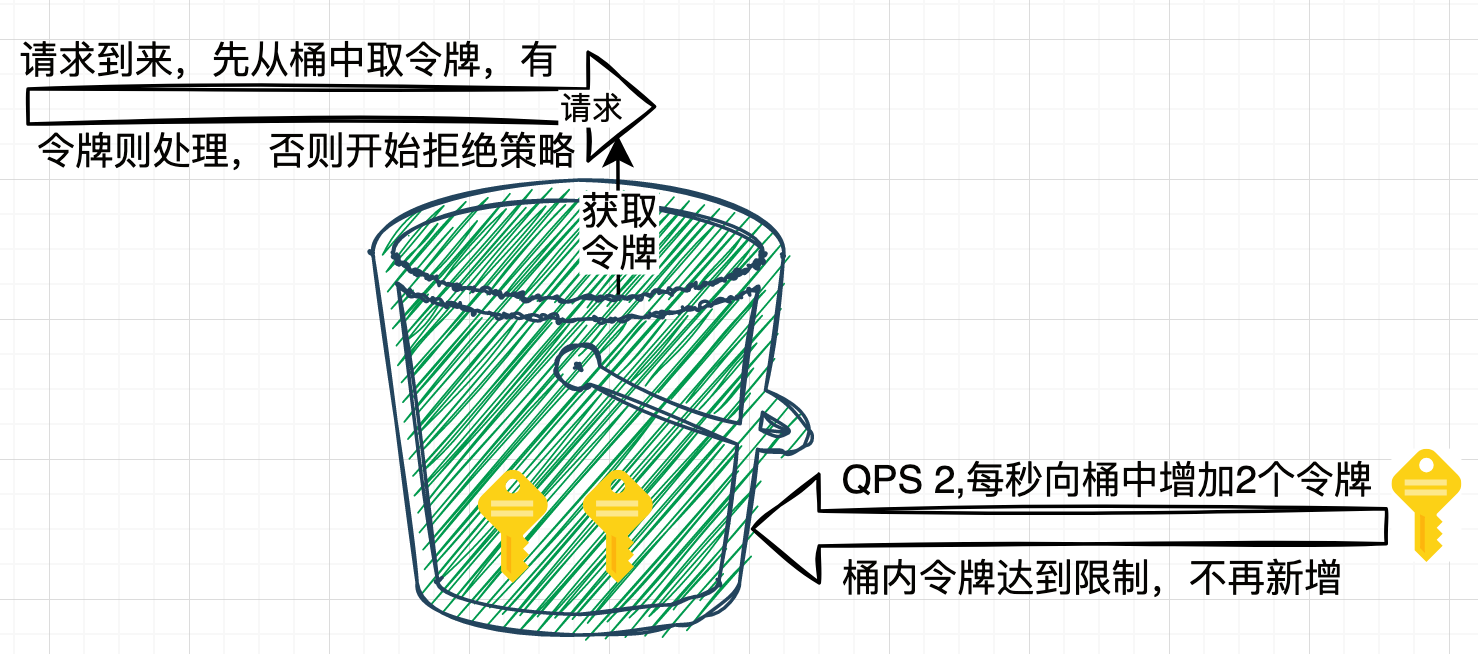
令牌桶算法(Token Bucket Algorithm)是一种流量控制算法,用于控制数据的发送速率。它基于一个令牌桶的概念,通过放置令牌到桶中来控制数据的发送。
在令牌桶算法中,桶以恒定的速率产生令牌,并将其放入桶中。每当有数据要发送时,发送方需要从桶中获取一个令牌,如果桶中没有可用的令牌,则需要等待或丢弃该数据。每个令牌代表一个数据包的发送权限,发送方只有在获取到令牌时才能发送数据。
令牌桶算法的核心思想是通过控制令牌的生成速率和桶的容量来控制数据发送的速率。如果发送方的速率超过了令牌的生成速率,那么多余的数据将无法获得令牌,从而限制了发送速率。
下面是令牌桶算法的示意图:
相关代码实现:
public class TokenBucket {
private final int capacity; // 桶的容量
private long tokens; // 当前令牌数量
private long lastRefillTime; // 上次令牌填充时间
private final long refillInterval; // 令牌填充时间间隔
public TokenBucket(int capacity, long refillRate, TimeUnit refillUnit) {
this.capacity = capacity;
this.tokens = capacity;
this.refillInterval = refillUnit.toMillis(1) / refillRate;
this.lastRefillTime = System.currentTimeMillis();
}
public synchronized boolean tryAcquire() {
refillTokens(); // 先填充令牌
if (tokens > 0) {
tokens--;
return true; // 获取令牌成功
}
return false; // 令牌桶为空,获取令牌失败
}
private void refillTokens() {
long currentTime = System.currentTimeMillis();
long elapsedTime = currentTime - lastRefillTime;
if (elapsedTime > refillInterval) {
long newTokens = elapsedTime / refillInterval; // 计算填充的令牌数量
tokens = Math.min(tokens + newTokens, capacity); // 更新令牌数量,不超过桶的容量
lastRefillTime = currentTime; // 更新上次填充时间
}
}
public static void main(String[] args) {
int capacity = 10; // 桶的容量为10
int refillRate = 2; // 每秒填充2个令牌
TokenBucket tokenBucket = new TokenBucket(capacity, refillRate, TimeUnit.SECONDS);
// 模拟请求获取令牌
for (int i = 0; i < 15; i++) {
if (tokenBucket.tryAcquire()) {
System.out.println("处理请求 " + (i + 1));
} else {
System.out.println("限流请求 " + (i + 1));
}
// 模拟请求处理时间
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
小结
在本编文章中我们介绍了限流的概念,以及不同的限流算法。不同的限流算法适用于不同的场景,选择适合场景的限流算法可以更好地保护系统资源、提供良好的服务质量和用户体验。同时,限流算法的选择还需考虑系统的具体需求、资源状况和性能指标。
以下是对各种限流算法在不同场景中的应用示例:
- 计数限流:适用于对请求的数量进行简单控制的场景,如每秒最多处理的请求数、每分钟最多发送的消息数量等。
- 固定窗口计数限流:适用于需要固定时间间隔内的限流控制的场景,例如每秒钟只允许处理一定数量的请求。
- 滑动窗口计数限流:适用于需要更精细的流量控制的场景,能够平滑处理流量峰值和突发请求的情况。可以设置窗口长度和滑动间隔来动态调整限流策略。
- 漏桶算法:适用于对请求的处理速率进行限制的场景,以固定的速率处理请求。可以用于平滑请求流量、保护系统资源、防止突发流量等。
- 令牌桶算法:适用于对请求的处理速率进行限制的场景,提供了更灵活的控制方式。允许短时间内处理突发请求,同时能够平滑处理请求速率的变化。