K8S kube-proxy运行机制解析
简介
对于使用Kubernetes的人来说,Pod是 Kubernetes 最小的部署单元。在集群中,每个Pod都会分配一个IP地址,它们共享一个网络地址空间(如下图)。每个Pod都可以通过其他Pod的IP地址来实现相互访问,它们之间不需要通过NAT(网络地址转换)。
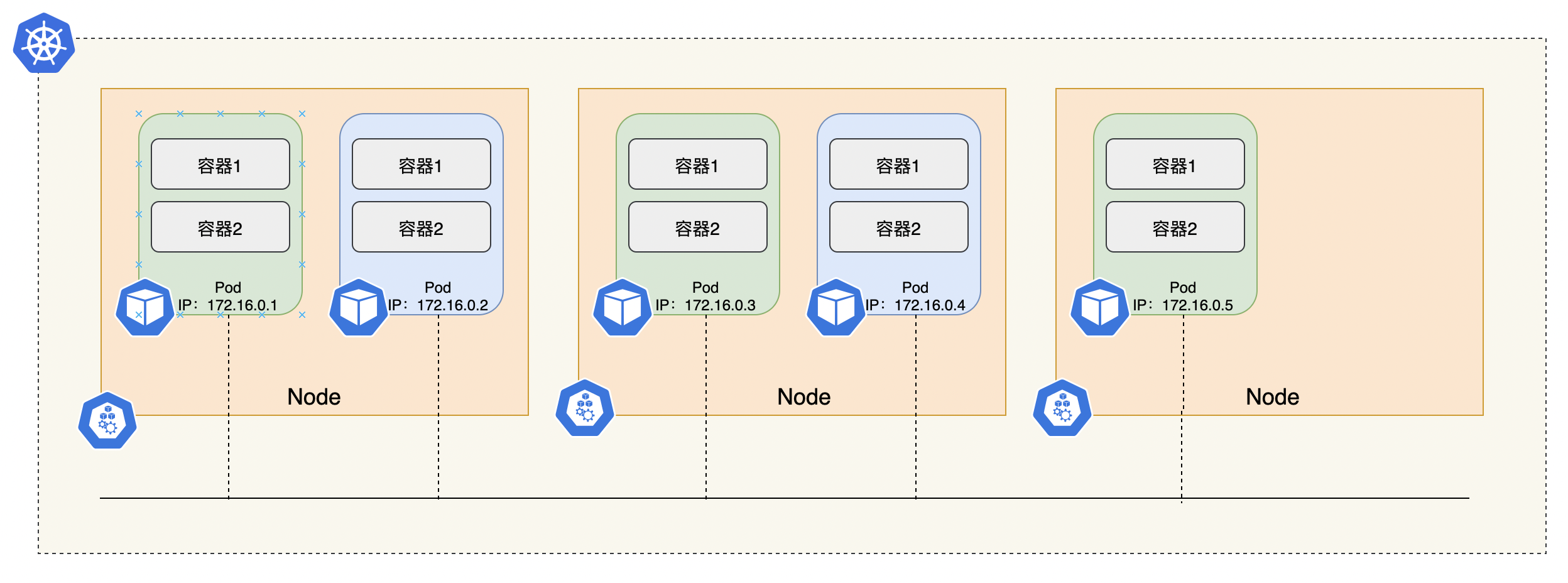
这种机制在kubernetes环境下存在如下特点:
- 一方面是因为Pod并是固定在某一个节点上的,Pod会出现销毁、漂移等情况,也就是说Pod的IP不是固定的;
- 另一方面,为了支持集群的水平扩展和高可用性Pod通常都是1~N个,需要通过负载均衡访问策略来访问这组Pod。
为了解决这种问题,kubernetes引入Service的概念。
Pod和Service之间的通信过程
kubernetes在创建Service时会为服务分配一个固定的、虚拟的IP地址,称为Cluster IP,客户端通过访问这个虚拟的IP地址来访问Service,Service负责将请求转发到后端的服务上。通过这段描述我们发现没有,Service是不是很像反向代理服务Nginx。但是,它和普通的反向代理有一些不同,它存在2种不能类型:
- 首先,它可以没有对应的物理实体,也就是说它是一种虚拟的逻辑资源
- ClusterIP类型: 将提供一个可以被集群内其他服务或容器访问的入口,支持TCP/UDP协议。比如:数据库类服务如Mysql可以选择集群内访问,来保证服务网络隔离性。
- NodePort类型:提供一个主机端口映射到容器的访问方式,支持TCP&UDP
- 其次,它也可以有对应的物理实体,在云厂商提供的容器服务上提供LoadBalancer类型的Service
- 公网LB类型:自动创建传统型公网LB以提供Internet访问入口,支持TCP/UDP协议,如web前台类服务可以选择公网访问。
- 内网LB类型:自动创建内CLB以提供内网访问入口,将提供一个可以被集群所在VPC下的其他资源访问的入口,支持TCP/UDP协议,需要被同一VPC下其他集群、云服务器等访问的服务可以选择VPC内网访问的形式。
如下图,可以看到kubernetes中Pod和Service之间的通信过程
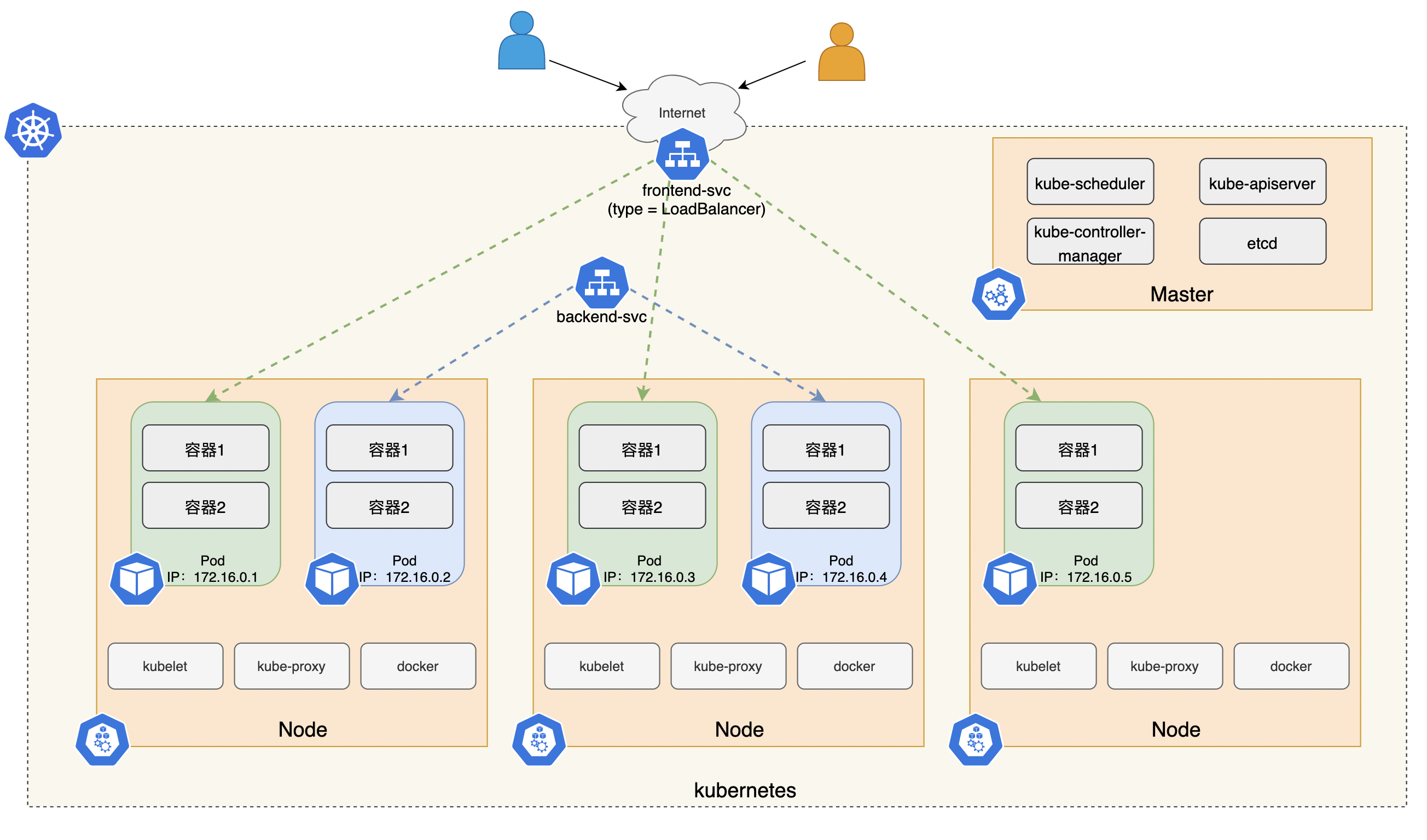
此时,我们会产生一个疑问:如果Service是一种虚拟的逻辑资源,那么如果把请求转发到Pod的呢?这个时候就轮到kube-proxy出场了。
Kube-proxy进程
在kubernetes集群中的每个Node都会运行一个kube-proxy服务进程,这个进程我们可以理解为Service的透明代理和负载均衡器,也就是就是通过它可以将某个内部Service的访问请求转达到后端的多个Pod实例上。
Kube-proxy作为一个网络代理组件,其工作原理主要有三种模式:userspace、Iptables、IPVS。当然,无论是哪种模式,Kube-proxy都提供了以下功能:
-
服务发现:Kube-proxy会监听Kubernetes API服务器上的服务和端点对象,以获取服务的信息。其中,Service对象定义了服务的名称、IP地址、端口等信息,而Endpoints对象定义了服务后端的Pod IP地址和端口信息。
-
负载均衡:Kube-proxy会根据服务的类型(ClusterIP、NodePort、LoadBalancer)来选择不同的负载均衡策略,并将请求转发到服务的后端Pod上。
-
请求转发:当客户端请求到达节点时,Kube-proxy会根据负载均衡规则将请求转发到后端Pod。
-
故障转移:Kube-proxy会检测后端Pod的健康状态,并在发现故障时自动将请求转发到其他健康的Pod上。
-
会话保持:在某些场景下,需要保证客户端与同一个后端Pod之间的会话保持。Kube-proxy可以通过Iptables模式下的–conntrack模块或IPVS模式下的–persistent-mode选项来实现会话保持。
需要注意的是,Kube-proxy只负责集群内部的服务代理和负载均衡,对于集群外部的服务访问,需要使用Kubernetes的Ingress或Service LoadBalancer等组件来实现
Kube-proxy运行机制
现在让我们看一个具体的流程图来理解kube-proxy运行机制,如下图:
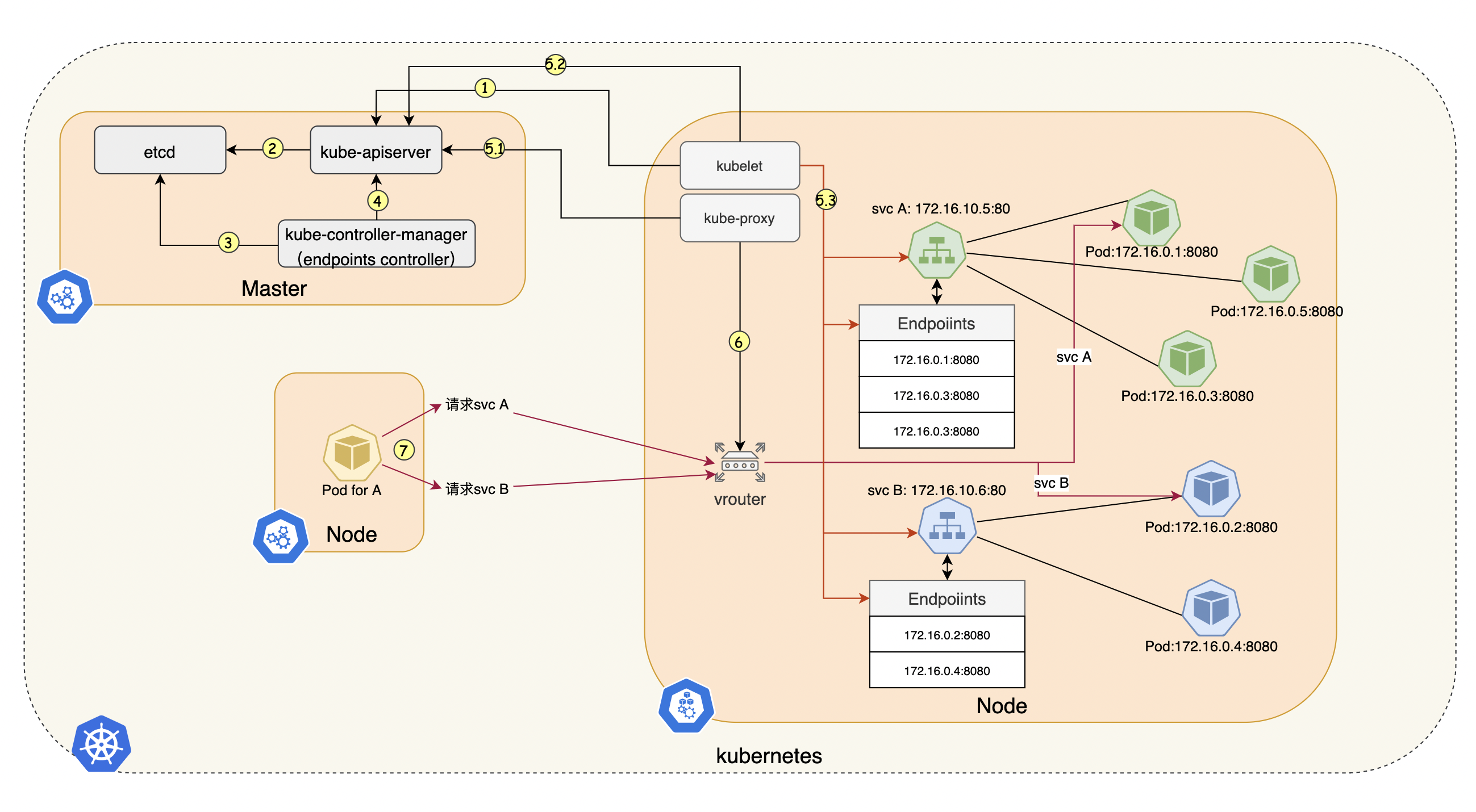
-
当Pod IP地址发生变化时,kubelet会通过向kubenetes API服务器发送一个更新事件来通知API服务。具体来说,Kubelet会在Node节点上通过kubelet API向API服务器发送一个PATCH请求,更新Pod的IP地址信息。
这个更新事件会包含以下信息:
-
Pod的名称和命名空间。
-
Pod的新IP地址。
-
Pod的标签和注释信息。
-
Pod的状态信息,如容器运行状态、重启次数等。
-
-
API服务器收到更新事件后,会将新的Pod IP地址信息保存到etcd中,保存的是Endpoints对象。
-
Kube Controller Manager和Endpoints Controller通过watch机制监听etcd中Endpoints对象的变化
- Endpoints Controller负责将服务对象和后端Pod信息进行关联,并将关联信息保存到etcd中。当服务对象发生变化时,Endpoints Controller会自动更新etcd中的关联信息,从而保证负载均衡和代理转发的正确性。
- Kube Controller Manager则负责监控Endpoints对象的变化,并根据Endpoints对象的变化来触发相应的操作。例如,当Endpoints对象发生变化时,Kube Controller Manager会自动更新相关的Service对象。
Kube Controller Manager和Endpoints Controlle之间没有固定的先后顺序,具体的执行顺序会根据事件的发生时间和处理时间来决定。它们是分别运行的独立控制器,Kube Controller Manager是一个集成了多个控制器的组件,而Endpoints Controller则是其中的一个控制器。
Kube Controller Manager在Kubernetes集群中扮演着很重要的角色,可以看作是Kubernetes的控制中心。它主要负责管理集群中的各种控制器,如Replication Controller、Service Controller、Endpoints Controller、Namespace Controller等,以保证集群的正常运行。
其中,Replication Controller负责管理Pod的副本数量,保证Pod的高可用性和可扩展性;Service Controller负责管理服务对象,为服务提供负载均衡和服务发现功能;Endpoints Controller负责管理服务的后端Pod信息,以保证负载均衡和代理转发的正确性;Namespace Controller负责管理命名空间,将集群资源划分为不同的逻辑部门。
Kube Controller Manager通过不断地监控集群状态,及时检测到各种异常情况,并采取相应的措施进行处理。例如,当某个Pod发生故障时,Replication Controller会自动启动新的Pod来代替故障的Pod,保证服务的可用性;当Service对象发生变化时,Service Controller会更新负载均衡规则,确保客户端请求能够正确地转发到后端Pod上。
-
Endpoints对象发生变化后,Kube Controller Manager和Endpoints Controller都需要通知Service对象,但它们通知Service对象的方式和目的略有不同
- Endpoints Controller根据Endpoints对象的变化来更新对应的Service对象。当Endpoints对象的IP地址或端口信息发生变化时,会在更新Endpoints对象后,向API服务器发送一个更新Service对象的请求,以通知API服务器更新Service对象的信息。API服务器接收到该请求后,会更新对应的Service对象,并将更新信息写入etcd数据库中,以便其他组件进行查询。
- Kube Controller Manager中的Service控制器负责监视Service对象的变化,并根据Service对象的变化来更新集群中的负载均衡器等相关组件(这些相关组件包括kube-proxy、ingress controller、NodePort service等相关组件都会进行调整)。
虽然Kube Controller Manager和Endpoints Controller都需要通知Service对象,但它们通知Service对象的方式和目的略有不同。Endpoints Controller主要是根据Endpoints对象的变化来更新对应的Service对象,而Kube Controller Manager中的Service控制器则主要是监视Service对象的变化,并根据Service对象的变化来更新集群中的相关组件。这两者是互相协作的关系,共同确保Service对象能够正确地将流量路由到最新的Pod IP地址上,并保证整个集群的负载均衡能够正常运行。
-
本地Node更新Service对象
-
kube-proxy会定期向API服务器发送一个watch请求,以监视Service对象的变化。如果Service对象发生变化,则会向kube-proxy发送一个事件通知。事件通知包含了Service对象的更新信息,例如Service对象的名称、IP地址、端口号、协议类型等信息。
Kube Controller Manager会主动通知kube-proxy和,kube-proxy会定期向API服务器发送一个watch请求
到底哪个说法正确?两个说法都是正确的。Kube Controller Manager会主动通知kube-proxy进行更新,而kube-proxy也会定期向API服务器发送watch请求来监视Service对象的变化。这两种方式的作用是一样的,都是为了确保kube-proxy能够及时获取Service对象的变化,并更新相应的负载均衡规则以保证服务的可用性。Kube Controller Manager通知的方式更加及时和精确,而kube-proxy发送watch请求的方式则能够及时感知Service对象的变化,这样即使Kube Controller Manager出现故障或延迟,kube-proxy也能够保持最新的负载均衡规则。
-
kubelet也会从API Server获取最新的Service和Endpoint对象信息,并同步到本地缓存中。当Service或Endpoint对象发生变化时,kubelet会将最新的对象信息同步到本地缓存中,并通知kube-proxy进行负载均衡规则的更新。
kube-proxy和kubelet都通过API Server获取最新的Service和Endpoint对象信息,并根据这些信息更新本地的负载均衡规则。kube-proxy会监听API Server的Watch事件来获取最新的对象信息,而kubelet会定期从API Server获取最新的对象信息并同步到本地缓存中。这在软件开发中是一个双保险。
-
-
kube-proxy会从本地缓存或者通过接收到事件通知中获取最新的endpoints和services对象信息,然后更新对象信息以及更新相应的负载均衡规则(本地的iptables或者IPVS规则),以确保Service对象能够正确地将流量路由到最新的Pod IP地址上。
-
某个Pod上的服务C分别访问A或者B服务
Kube-proxy网络代理模式
userspace模式
在Kubernetes早期版本中,Kube-proxy还支持一种叫做userspace模式的负载均衡方式。该模式通过在节点上启动一个userspace进程来实现服务的负载均衡和代理转发。具体来说:
- 当kube-proxy在工作节点上启动后,就会监听kube-apiserver上Service和endpoints资源的变化情况,之后会针对每个service(每个协议、Service IP、Service端口)在节点上随机创建一个监听端口(这个端口实质上是一个Socket套接字),并在iptables中配置规则,这些规则会将目的地址是Service的IP:端口的请求转发给运行在用户空间的kube-proxy进程
- 当用户访问服务时,请求首先被发送到Kube-proxy的userspace进程。该进程会根据服务的类型(ClusterIP、NodePort、LoadBalancer)来选择不同的负载均衡策略,并将请求转发到服务的后端Pod上。
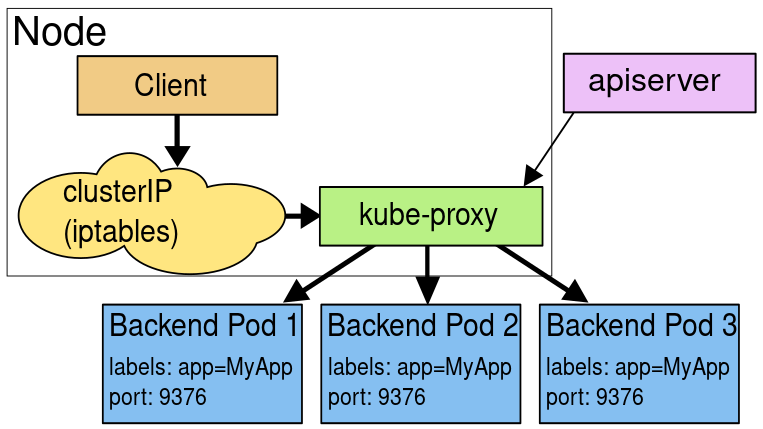
userspace模式的优点是实现简单,不需要依赖复杂的内核技术。但是该模式的缺点也很明显,由于使用的是userspace进程来处理请求,请求需要在用户空间和内核空间来回转移,因此性能较差,且难以扩展到大规模的集群。
用户代理模型的历史非常短,在Kubernetes的v1.2版本中就被iptables模型取代成为新的默认选项。
iptables模式
iptables从Kubernetes v1.2版本开始称为kube-proxy的默认模式,它基于Linux系统的iptables技术实现。它将每个节点上的容器都分配一个唯一的IP地址,并使用iptables规则来实现容器之间的通信和网络隔离。
与用户空间代理模型不同的是,iptables代理模型中kube-proxy仅负责监听Service、endpoints等资源的变化,并将这种变化同步到iptables中的规则表中,不再参与请求的转发和负载均衡工作。这些工作均由iptables来完成,所以请求会一直在内核空间中传递,不必再被转入用户空间的kube-proxy进程中。
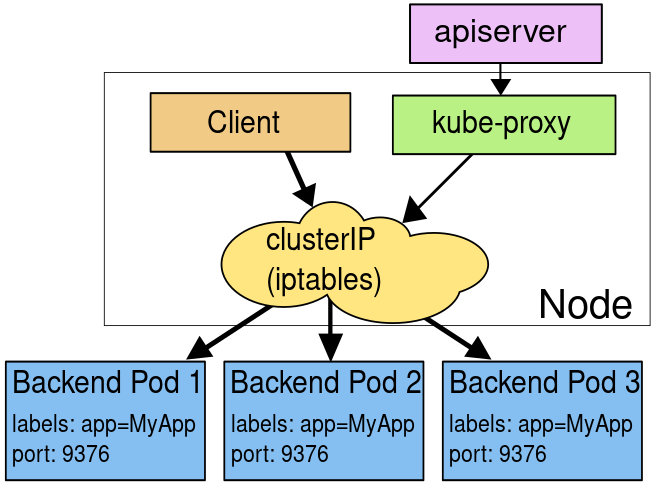
iptables工作在第三层(网络层)和第四层(传输层)上,根据IP地址、端口号、协议等信息进行流量控制和转发。
可以看到iptables模式具有简单、灵活性高等优化,但它也存在很明显的缺点。
优点:
-
成熟稳定:iptables是一种成熟、稳定的技术,在Linux系统中得到广泛应用,因此Iptables模式在稳定性和可靠性方面表现良好。
-
灵活性高:Iptables模式可以通过iptables规则来实现容器之间的通信和网络隔离,可以根据具体的需求制定不同的规则,具有良好的灵活性。
-
安全性高:Iptables模式可以为每个容器创建一条iptables规则,只允许该容器的流量通过,从而确保容器之间的通信是安全和隔离的。
-
可扩展性好:Iptables模式可以方便地扩展到大规模集群中,通过添加更多的节点和代理程序(kube-proxy),可以轻松地扩展到数千个容器。
缺点:
-
性能问题:由于iptables规则可能非常复杂,因此在大规模集群中可能会出现性能问题。特别是当iptables规则需要频繁更新时,会对系统性能造成负面影响。
-
复杂性高:Iptables模式需要使用iptables规则来实现容器之间的通信和网络隔离,这需要一定的技术和经验,对于新手来说可能比较复杂。
-
配置复杂:Iptables模式需要在每个节点上运行一个代理程序kube-proxy,这需要进行相应的配置和管理,增加了系统的复杂性和管理成本。
综上所述,Iptables模式是一种成熟稳定、灵活性高、安全性高的网络模式,但也存在性能问题和配置复杂等缺点。在选择网络模式时,需要根据具体的需求和环境进行综合考虑,选择最适合自己的网络方案。
IPVS(IP virtual server)模式
kubernetes从v1.8版本开始引入第三代的IPVS模式,并且在在v1.12版本中正式取代iptables成为新的kube-proxy默认工作模式。
- IPVS模式是一种负载均衡技术,它使用Linux内核中的IPVS(IP Virtual Server)模块来进行流量分发和负载均衡。
- IPVS工作在第四层(传输层),即TCP/UDP协议层上,根据流量的源地址、目标地址、端口等信息进行流量分发。
- IPVS使用一系列负载均衡算法(如轮询、源地址哈希、最小连接数等)来分发流量,以实现高效的负载均衡
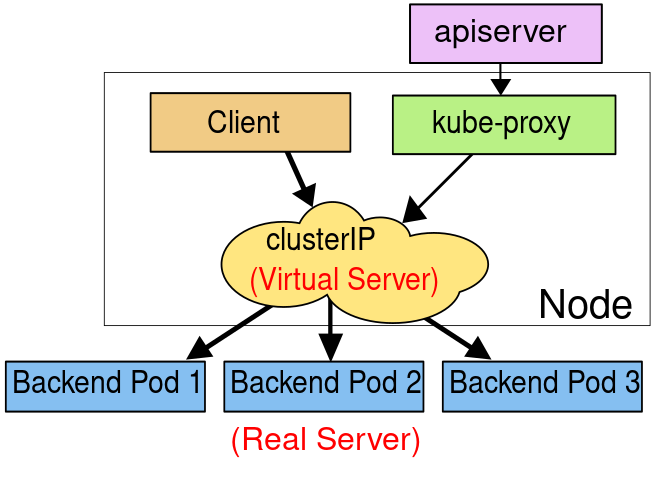
使用IPVS模式的好处包括:
- 高性能:IPVS模块使用内核级别的负载均衡算法,可以实现高性能的流量分发和负载均衡。
- 稳定性:IPVS模式可以自动检测后端Pod的状态,如果某个Pod出现故障,IPVS模块会将流量自动转发到其他可用的Pod,实现高可用性。
- 灵活性:IPVS模式支持多种负载均衡算法,并且可以与Kubernetes的服务发现机制集成,可以很方便地进行配置和管理。
- 可扩展性:IPVS模式可以与Kubernetes的水平扩展机制(如HPA)结合使用,可以根据负载情况自动扩展后端Pod的数量,实现自动化的负载均衡。
小结
K8S kube-proxy是Kubernetes的一个组件,用于实现Kubernetes Service的负载均衡和反向代理功能。它的运行机制如下:
-
kube-proxy会在每个节点上启动一个代理进程,该进程会监听Kubernetes apiserver中Service和Endpoint的变化。
-
当Service或Endpoint发生变化时,kube-proxy会更新本地的iptables规则或IPVS规则,以实现负载均衡和反向代理功能。具体来说,它会将Service的Cluster IP映射到后端的Pod IP,并将请求转发到对应的Pod上。
-
kube-proxy当前只支持两种模式:iptables模式和IPVS模式。在iptables模式下,kube-proxy会使用iptables规则来实现负载均衡和反向代理;而在IPVS模式下,kube-proxy会使用IPVS规则来实现负载均衡和反向代理,这种模式相比iptables模式更加高效。
-
kube-proxy还支持多种负载均衡算法,如Round Robin、Least Connection等。在配置Service时,可以通过设置Service的spec.loadBalancerAlgorithm字段来指定负载均衡算法。
总之,K8S kube-proxy是Kubernetes的一个重要组件,它通过监听Service和Endpoint的变化,并更新本地的iptables规则或IPVS规则,实现负载均衡和反向代理功能。同时,它还支持多种负载均衡算法和两种模式,可以根据实际需求进行定制和配置。