Kafka源码解读
前言
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka也是一种高吞吐量的分布式发布订阅消息系统,其核心组件包含Producer、Broker、Consumer。在2.8版本前强依赖Zookeeper集群,新的版本内部基于KRaft模式,一部分Broker被指定为控制器。不管是Zookeeper还是kRaft模型,它们都是提供分布式共识服务,是Kafka用来负责集群元数据的管理、控制器的选举等的。
本文基于kakfav2.8.2版本源码进行的阅读,通过阅读源码可以让我们更深入地理解kafka内部设计原理以及分布式系统设计思路及实现方式,提升我们的系统架构能力。
源码构成
kafka源码主要由scala和java代码编写。
从源码目录上看:
-
bin 目录:保存 Kafka 工具行脚本,我们熟知的 kafka-server-start 和 kafka-console-producer 等脚本都存放在这里。
-
clients 目录:保存 Kafka 客户端代码,比如生产者和消费者的代码都在该目录下。
-
config 目录:保存 Kafka 的配置文件,其中比较重要的配置文件是 server.properties。
-
connect 目录:保存 Connect 组件的源代码。我在开篇词里提到过,Kafka Connect 组件是用来实现 Kafka 与外部系统之间的实时数据传输的。
-
core 目录:保存 Broker 端代码。Kafka 服务器端代码全部保存在该目录下。
-
streams 目录:保存 Streams 组件的源代码。Kafka Streams 是实现 Kafka 实时流处理的组件。
从功能上讲主要分为四个部分:
-
服务器端源码:主要以scala代码编写,实现kafka架构Broker端
-
客户端源码:主要以java代码编写,定义了与Broker端交互机制,以及通用的Broker端组件支撑代码。
-
Connnect源码:用于实现kafka与外部系统的高性能传输
-
Streams源码:用于实现流处理能力,Apache Spark可以与Kafka一起用于流式传输数据
关键组件
每个kakfa broker启动时都会构造kafkaServer对象并启动。如图:
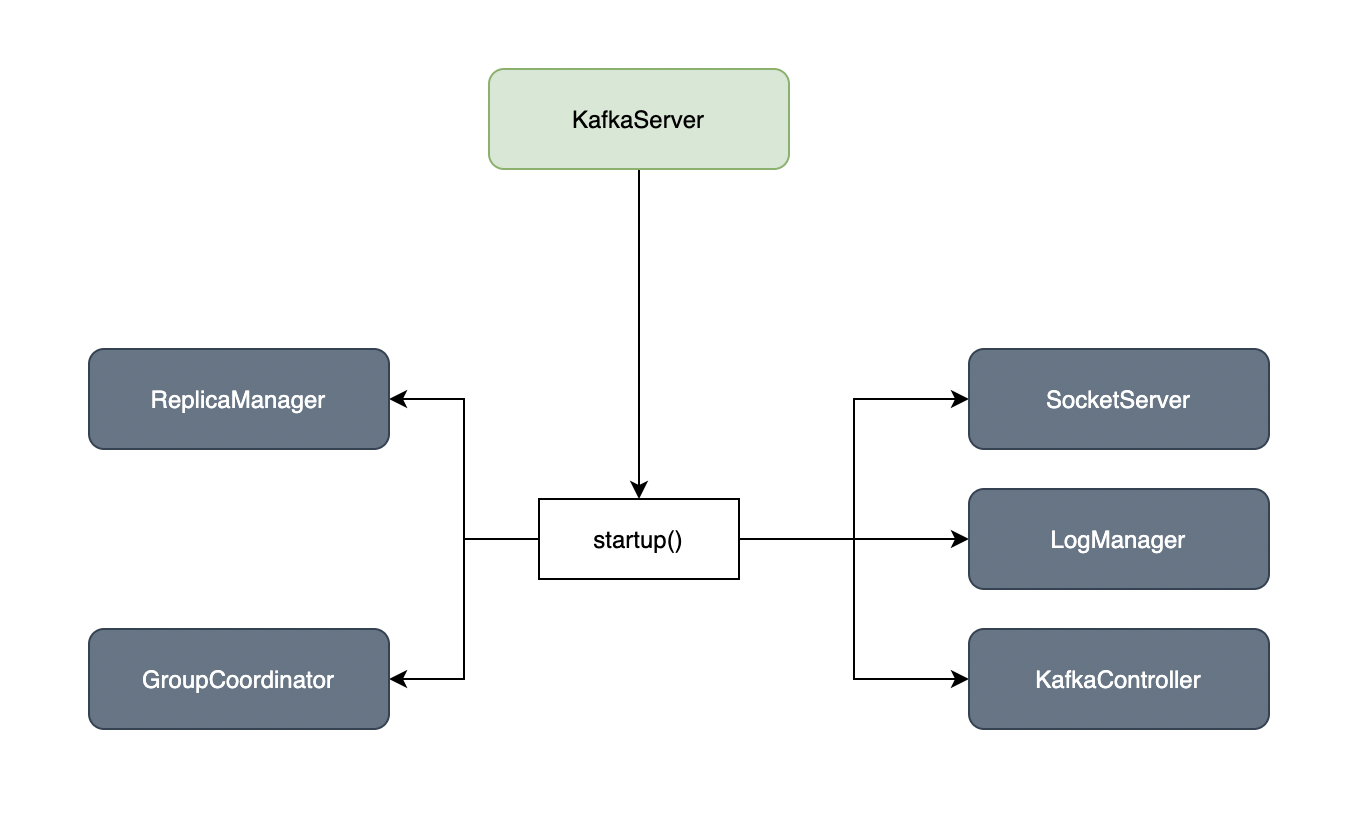
kafkaServer启动时,会初始化一些核心组件:
- 网络通信组件(SocketServer): 基于NIO构建网络通信框架。接受客户端/其他broker节点请求,交由
Acceptor线程处理外部TCP连接。已建立连接socket通过Processor线程处理读写。 - 控制器组件(KafkaController): 为集群中所有主题分区选择领导者副本;另一方面,还承载着集群的全部元数据信息,并负责将这些元数据同步到其他Broker上。
- 日志管理组件(LogManager): 管理每个主题分区所有日志读写,以及相关日志元数据管理。每个主题分区在单个
broker上有且仅有一个。 - 副本管理组件(ReplicaManager): 负责管理和操作集群中 Broker 的副本,还承担了一部分的分区管理工作,比如变更整个分区的副本日志路径等
- 消费者组协调器组件(GroupCoordinator): 用于协调多个消费者之间能够正确地工作的一个角色, 比如计算消费的分区分配策略,又或者消费者的加入组与离开组的处理逻辑
小结
我们了解kafka源码的结构,同时归纳总结了一份要想深入了解和学习kafka源码的关键路径是需要掌握5个核心组件。网络通信组件是底层的基座,通过此组件学习我们可以掌握客户端请求/响应完整流程。控制器组件是在所有broker中选举一个作为控制器,通过控制器可能让所有broker节点达成共识,比如ISR副本信息、主从节点信息等数据。日志管理组件用于持久化消息数据,提升系统可用性。副本管理组件负责kafka主题分区副本的管理。每个消费者都和消费者协调器进行交互,包括了新加入组客户端、组内消费客户端重平衡以及管理消费者已消费偏移量,并存储至__consumer_offset中。