深入Kafka副本机制
Kafka中采用了多副本机制啊,也即分布式系统中数据复制概念,以此来实现集群的水平扩缩达到容灾,提升整个集群的可用性及可靠性。
对于分布式系统来说,存在多个节点,各个节点间会存在各种故障。比如节点失效、节点发生切换、数据同步出现了延迟等问题。那么要做到高可用性,Kafka副本机制是如何解决这些问题的?
副本剖析
Kafka从0.8版本开始为分区引入多副本机制(Replica), 通过副本数可以提升容灾能力。同一分区副本数保存相同消息,副本之间是一主多从关系,其中Leader副本负责读写请求,Follower副本只负责与Leader副本消息同步,副本位于不同Broker上,当Leader副本出现故障时,从Follower副本重新选举新的副本提供对外服务
如下图,Kafka集群中有3个broker,某个主题有3个分区,每个分区有3个副本分别位于broker 0、 broker 1、broker 2节点中,其中带阴影的表示Leader副本
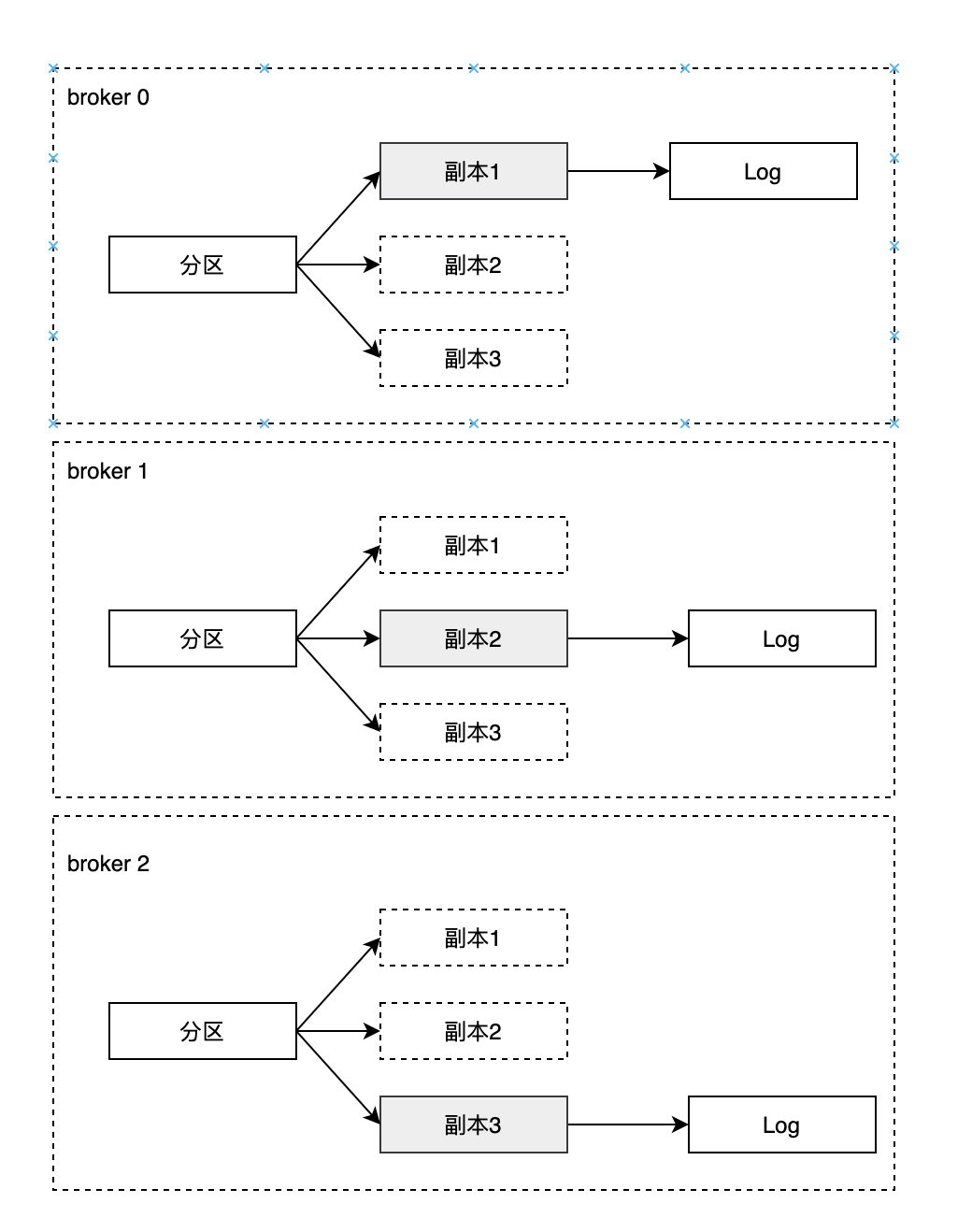
一个分区中包含一个或者多个副本,其中一个为leader副本,其余为follower副本,各个副本位于不同broker节点中。所有客户端读写请求会先发送给Leader副本所在Broker进行处理,Follower副本只需要从Leader副本异步拉取消息,并写入到自己的提交日志中,从而实现副本同步。
现在假设,我们有一个客户端向leader副本1写了8条消息。第一条消息的offeset(LogStartOffset)为0, 最后一条消息offset为8,offset为9消息用虚线框表示,代表下一条代写入消息。其中,follower1已经从leader副本拉取消息offset为5,follower2从leader拉取消息为3,3个副本都在ISR集合中。
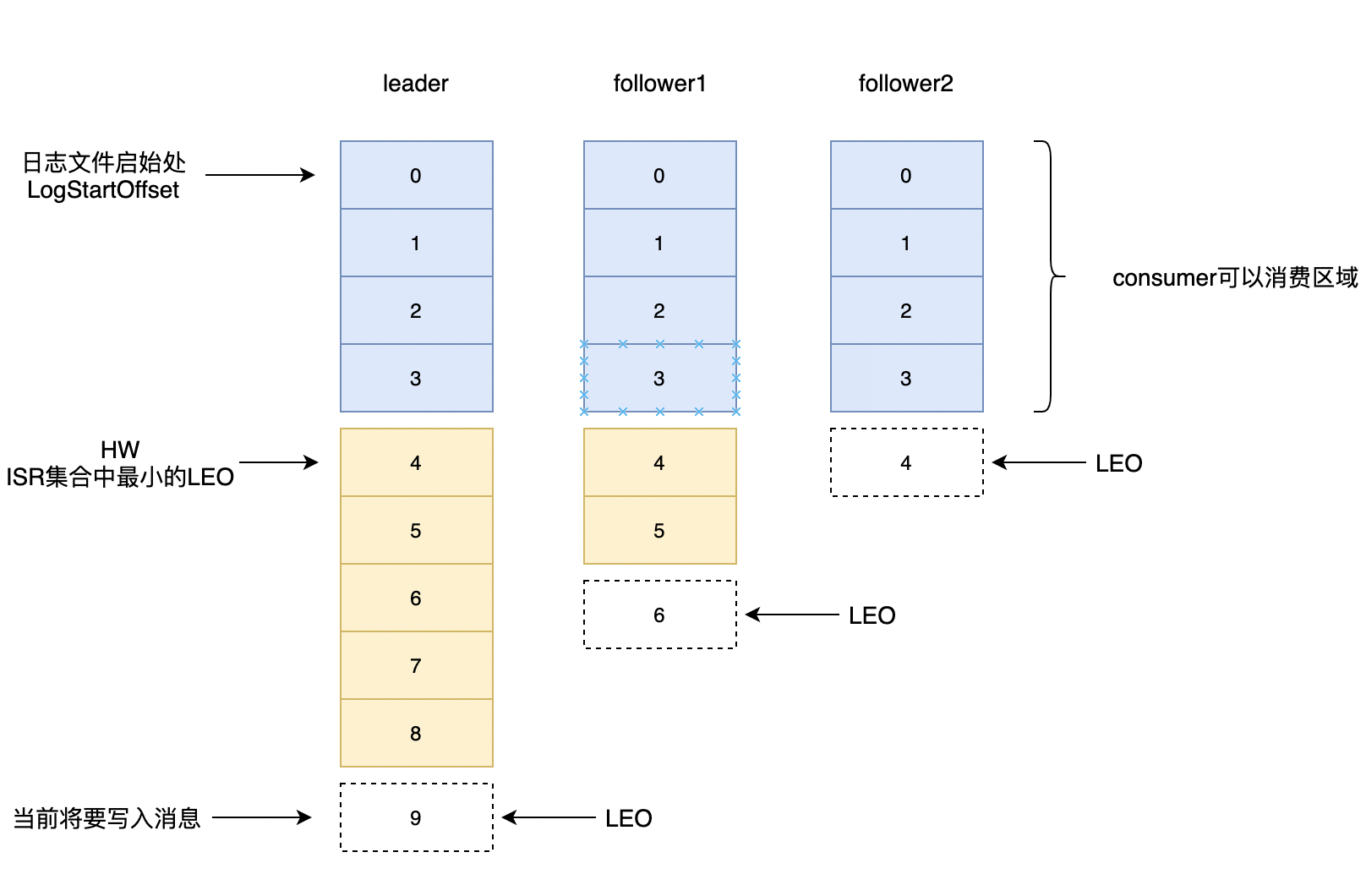
现在让我们来理解如下概念:
- AR:全称
Assigned Replicas,表示分区中所有的副本 - ISR:全称
In-Sync-Repllicas,表示所有与Leader副本保持一定同步的的副本,极端情况下ISR副本中可能只有Leader副本。ISR集合是AR集合中的一个子集。 - OSR:全称
Out-of-Replicas,表示所有与Leader副本存在滞后也就是数据不同步的副本,也称失效副本 - LEO:全称
Log End Offset,表示副本中最后一条消息的offset值加1。如果是leader副本表示将要写入消息的offset,如果是follower副本则表示将要从leader副本同步的下一个消息offset - HW:全称
High Watermark,ISR集合中最小的LEO既为分区的HW,对消费者而言只能消费HW之前的消息
由此可见,AR=ISR+OSR。在正常情况下,所有follower副本应该与leader副本保持数据同步,即AR=ISR,OSR为空。读到这,很多人会问,kafka中是如何确认副本存在于哪个子集的呢?
失效副本
所有从ISR集合中移除的副本,都会新增到OSR集合中。这些副本要么处于同步失效、要么功能失效,但我们都统称为失效副本。
在kafka的broker端有个参数:replica.lag.time.max.ms,这个参数含义是follower副本落后于leader副本的最长时间间隔,当前默认值是10s。如果一个follower副本上次从leader副本拉取消息的时间大于这个参数,就表示follower副本同步的速度慢于Leader副本的消息写入速度,leader副本会把它从ISR集合中剔除。
先让我们来看下kafka源码中Replica.scala和Partition.scala的2个函数:
// Replica.scala: follower副本每次从leader副本拉取完消息,都会调用此函数,更新相关变量
def updateFetchState(followerFetchOffsetMetadata: LogOffsetMetadata,
followerStartOffset: Long,
followerFetchTimeMs: Long,
leaderEndOffset: Long): Unit = {
/* 消息拉取存在三种情况:
* 1. 消费者拉取每次拉取消息都是生产者最新生产消息,也即followerFetchOffsetMetadata.messageOffset >= leaderEndOffset
* 2. 消费者拉取消息至少大于上次生产者最新的消息,
* followerFetchOffsetMetadata.messageOffset >= lastFetchLeaderLogEndOffset
* 3. 生产者生产消息远大于消费者拉取消息,就算follower一直不断拉取也不能与leader同步。如果还将此副本置于ISR集合中,
* 那么当leader副本下线而选取此副本为新的leader副本会导致消息丢失
* 4. 生产者没有生产消息,消费者每次拉取到的消息offeset为0
* 1和2都需要更新_lastCaughtUpTimeMs,也即上次拉取到消息的时间。这个变量用于判断follower副本是否需要从ISR中移除
*/
if (followerFetchOffsetMetadata.messageOffset >= leaderEndOffset)
_lastCaughtUpTimeMs = math.max(_lastCaughtUpTimeMs, followerFetchTimeMs)
else if (followerFetchOffsetMetadata.messageOffset >= lastFetchLeaderLogEndOffset)
_lastCaughtUpTimeMs = math.max(_lastCaughtUpTimeMs, lastFetchTimeMs)
_logStartOffset = followerStartOffset // 日志文件启始处
_logEndOffsetMetadata = followerFetchOffsetMetadata
lastFetchLeaderLogEndOffset = leaderEndOffset
lastFetchTimeMs = followerFetchTimeMs // 上次拉取时间
}
...
// Partition.scala: 判断一个follower副本是否需要从ISR中移除
private def isFollowerOutOfSync(replicaId: Int,
leaderEndOffset: Long,
currentTimeMs: Long,
maxLagMs: Long): Boolean = {
val followerReplica = getReplicaOrException(replicaId)
// 如果follower消息与leader消息不一致且
// follower副本上次拉取时间与当前间隔时间差值如果大于replica.lag.time.max.ms也即maxLagMs,那么就需要从ISR中剔除
followerReplica.logEndOffset != leaderEndOffset &&
(currentTimeMs - followerReplica.lastCaughtUpTimeMs) > maxLagMs
}
...
倘若,follower副本“追上”了leader副本,那么leader副本会把它从
OSR集合中转移到ISR集合中。这表明,ISR是一个动态调整的集合,而非静止不变的。新增副本同样适用于以上函数,只有当追赶上leader副本才会转移
private def maybeExpandIsr(followerReplica: Replica, followerFetchTimeMs: Long): Unit = { val needsIsrUpdate = canAddReplicaToIsr(followerReplica.brokerId) && inReadLock(leaderIsrUpdateLock) { needsExpandIsr(followerReplica) } if (needsIsrUpdate) { inWriteLock(leaderIsrUpdateLock) { // check if this replica needs to be added to the ISR if (needsExpandIsr(followerReplica)) { expandIsr(followerReplica.brokerId) } } } } // 如果follower副本LEO大于等于ISR集群的当前分区的HW,那么副本将被添加到ISR中 private def isFollowerAtHighwatermark(followerReplica: Replica): Boolean = { leaderLogIfLocal.exists { leaderLog => val followerEndOffset = followerReplica.logEndOffset followerEndOffset >= leaderLog.highWatermark && leaderEpochStartOffsetOpt.exists(followerEndOffset >= _) } }
更新LEO和HW
在每一个分区中,leader副本所在节点会记录自己的HW和LEO值,以及follower副本的LEO(用于帮助leader副本确定其HW,也就是分区HW),而follower副本所在节点只会记录自己的LEO和HW值。
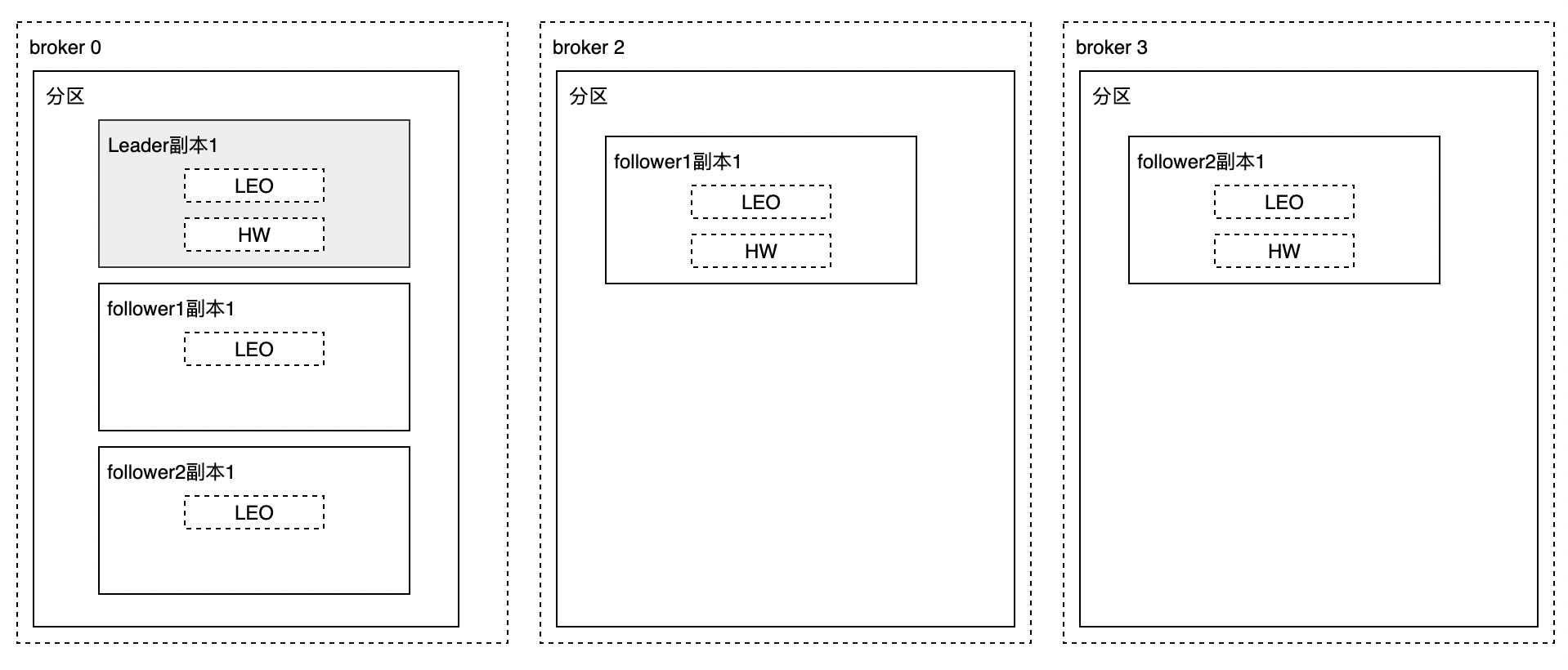
接下来我们以上图broker 0、 broker 1、broker 2为例,客户端需要写入消息到broker0上副本1,整个消息追加的过程可以概括如下:
- 生产者客户发送消息至leader副本(副本1)中
- 消息被leader追加到本地日志中,同时更新日志偏移量
- follower副本(broker2、broker3副本1)向leader副本请求同步数据
- leader副本读取所在服务器本地日志,并发送给follower副本
- follower副本收到leader副本返回结果,将消息追加到本地日志,并更新日志的偏移量信息
这个过程中,各个副本LEO和HW又是什么变化情况?
-
初始情况下,没有消息写入
LEO=0,HW=0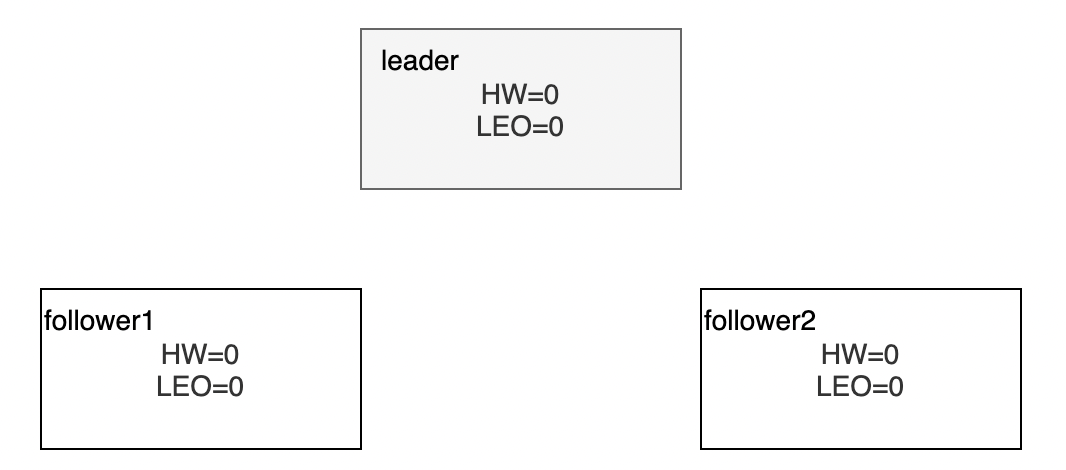
-
向leader副本写入4条消息,leader副本
LEO=5;follower1和follower2分别向Leader同步消息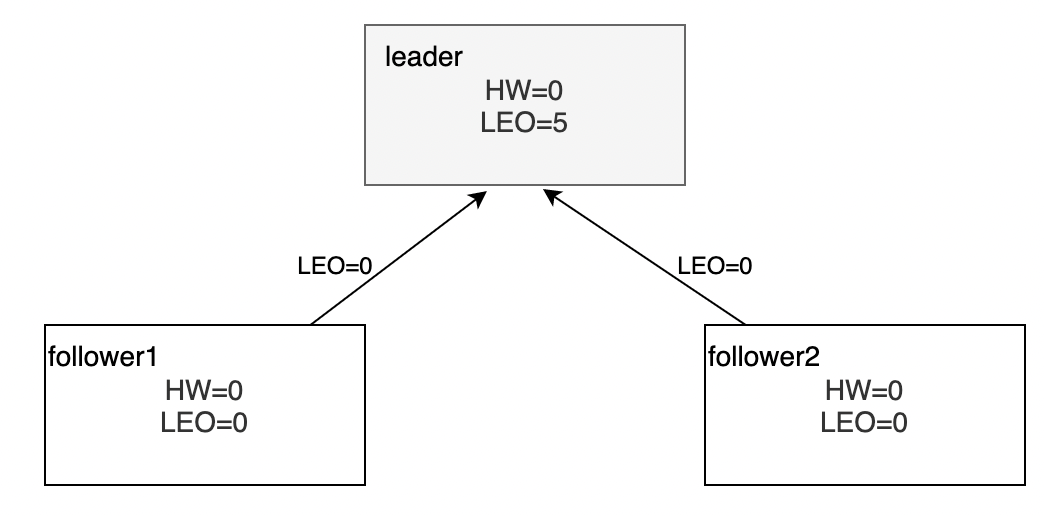
-
follower1拉取到2条消息,更新
LEO=3;follower2拉取到拉取到3条消息,更新LEO=4;同时客户端继续向leader写入5条消息,更新LEO=10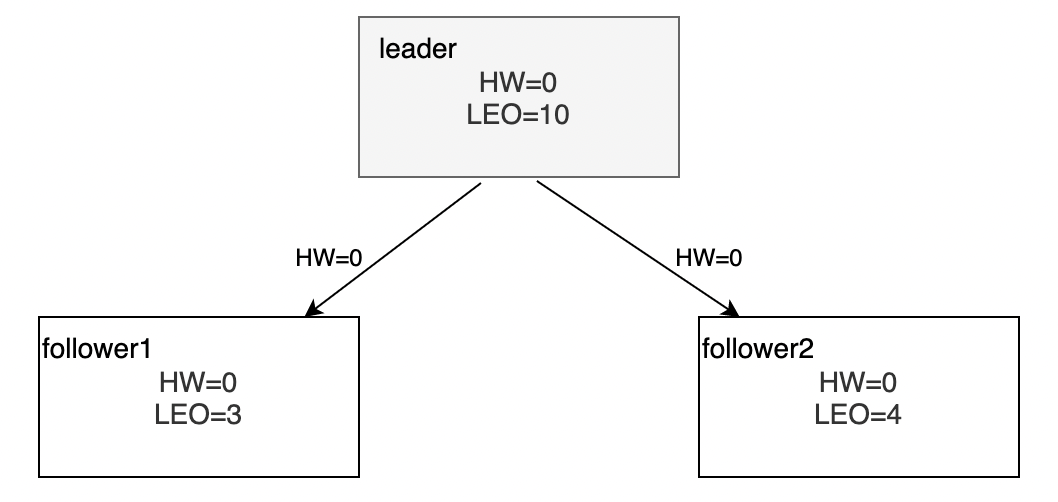
follower副本同时更新自己的HW,更新HW算法是比较当前LEO和leader副本传送过来的HW的值,取较小值作为自己的HW值。也既
min(0,0) = 0 -
接下来follower继续拉取leader副本消息,follower副本发在FetchRequest请求中带上自己的LEO信息。此时leader副本继续接受新的消息,更新LEO=15
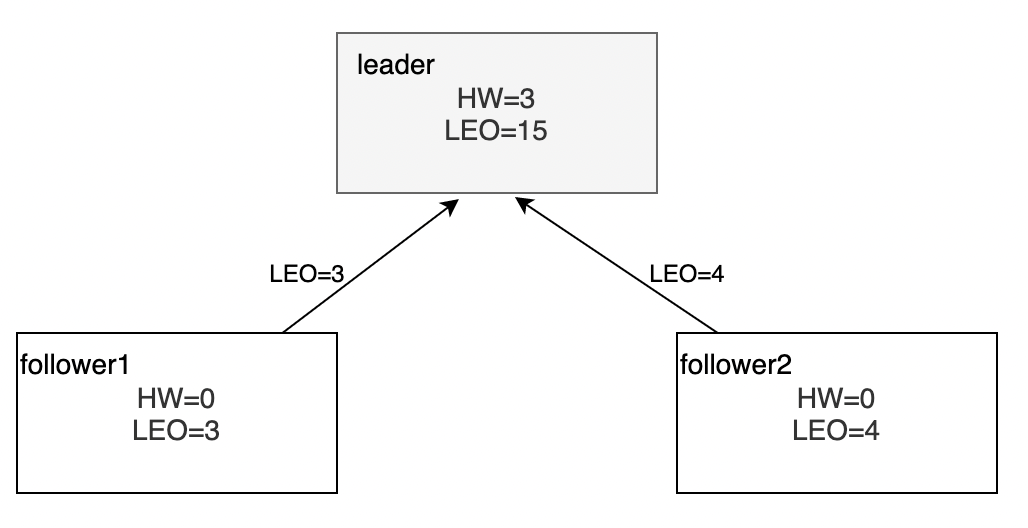
leader副本选取3个副本中最小的LEO作为自己的HW值,既HW=min(15, 3, 4) = 3
-
leader副本响应follower副本请求,通过FetchResponse给follower副本发送HW和消息
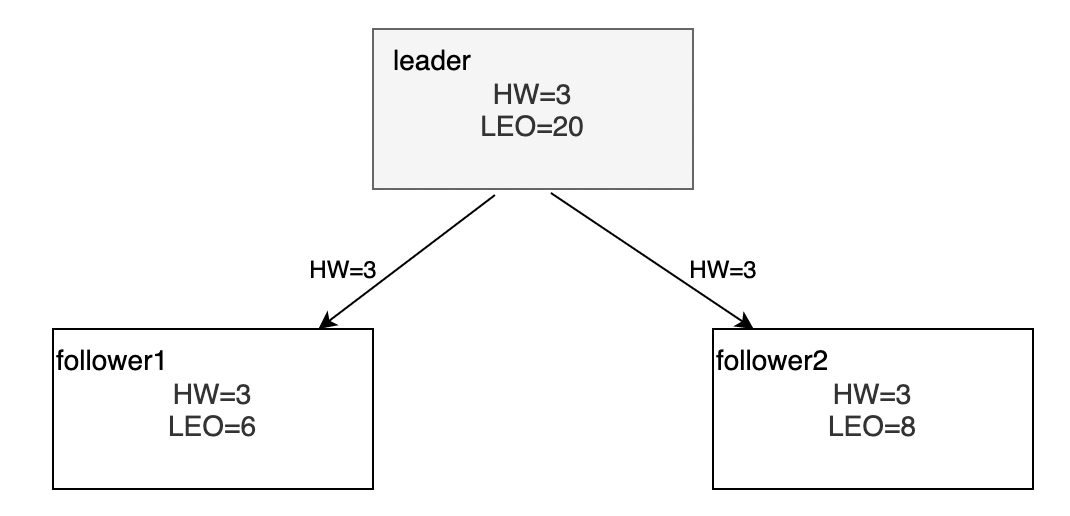
两个follower副本在收到新的消息之后更新LEO并且更新自己的HW为3,既
min(LEO,3)=3
上述操作,是leader副本与follower副本正常的同步过程。但正如我们说过,分布式系统是存在各种故障的。如果在同步过程中leader副本发送切换,那么同步又该如何处理?
数据同步的问题
前面一节主要陈述了在正常情况下leader副本与follower副本间的同步过程。如果leader副本发生切换,那么同步过程又会出现什么问题?我们先来看下数据可能丢失的场景。
让我们来看一个例子,副本A为leader副本,副本B为follower副本。
-
某一初始状态下,副本A和B相关信息:
offset=2, HW=2, LEO=3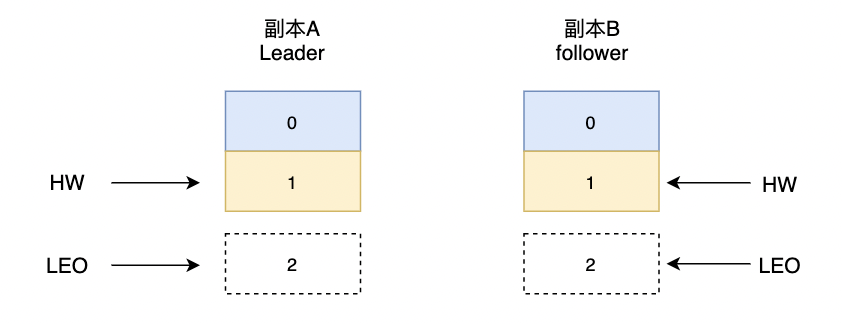
-
在某一时刻,副本B从副本A发送拉取消息请求,副本B发送FetchRequet请求,同时带上自己的**
LEO=3**数据;副本A继续接受客户写入请求,此时副本A更新数据:offset=4, HW=2,LEO=5。副本B请求和客户端更新消息请求是并发过程,不分先后顺序。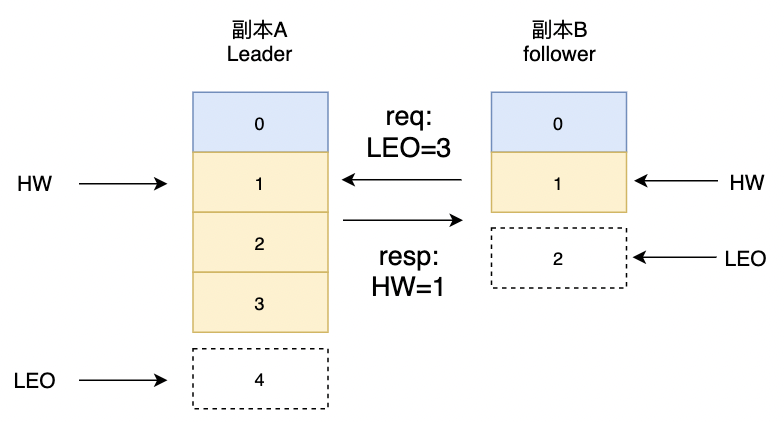
-
副本B收到FetchResponse响应,更新数据:
offset=3, HW=2, LEO=4,继续向副本A拉取消息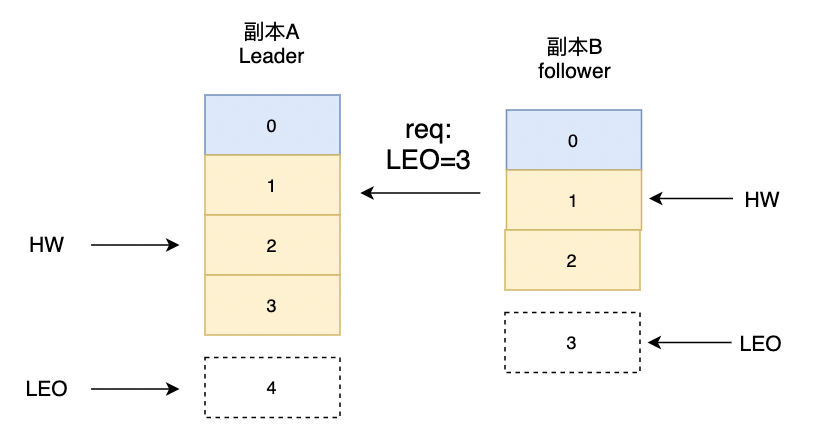
-
副本B重启,未接收到副本A发送FetchResponse。副本B在重启之后会根据之前HW位置进入日志截断
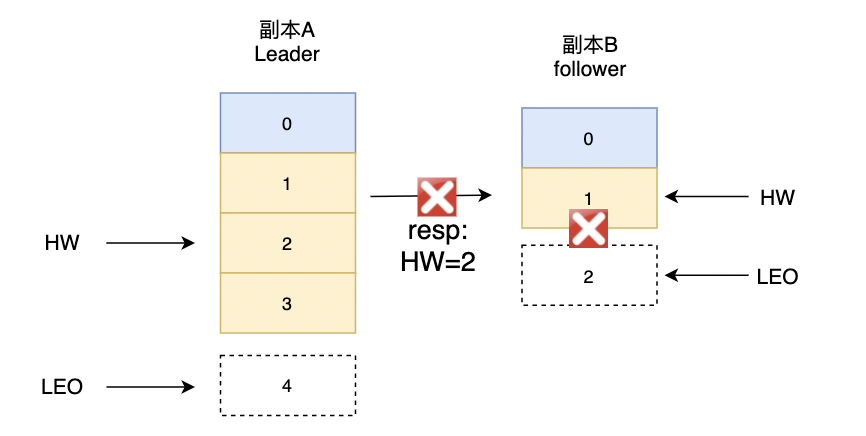
-
副本A宕机,副本B被选举为Leader。副本A恢复后会成为follower。由于follower副本HW不能比leader副本的HW高,所有副本A会进行一次日志截断,以此调整副本A
HW=1。此时,就出现了数据丢失的现象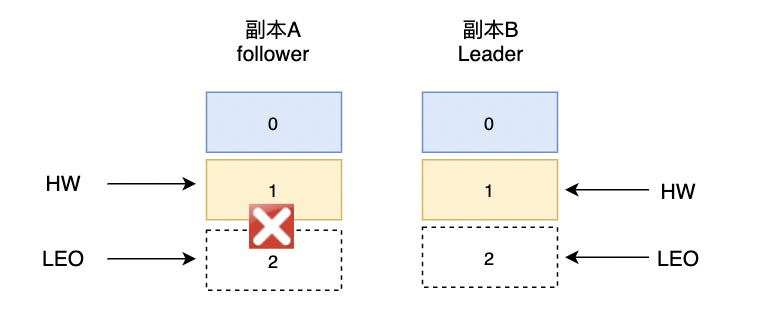
上面这种场景,一般发送的前提是Broker端参数min.insync.replicas=1,消息一旦被写入到leader磁盘,就会被认为是“已提交状态”。对于这种情况,我们能想到解决方案:
- 比如等待所有follower副本都更新完自身的HW之后再更新Leader副本的HW,但是这样会多一轮FetchRequest/FetchRespose。
- follower副本重启恢复数据时,需要先请求Leader副本数据,再截断自身
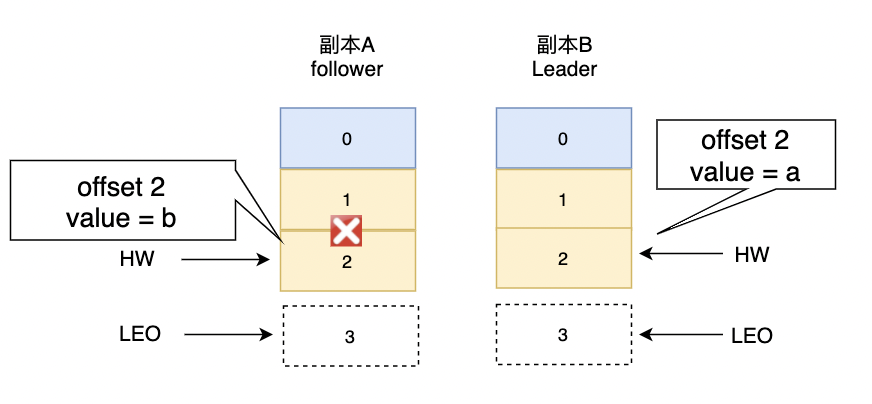
不过这种情况也可能会出现数据不一致。如下图
现在假设A,B副本都同时挂掉了,副本B先恢复被选举为leader,写入offset=2位置value=a并将HW更新至2。随后,副本A重启恢复并根据HW截断日志及发送FetchRequest消息至副本B,不过此时A的HW正好也为2,那么就可以不做任何调整。
引入Leader Epoch
为了解决数据同步的问题,kafka从0.11.0.0开始引入了leader epoch的概念,在需要截断数据的时候使用leader epoch作为参考,而不是原本的HW。
Leader epoch代表leader的纪元信息(epoch),初始值为0。每当leader变更一次,leader epoch的值就会加1,相当于版本号。同时每个副本增设一个矢量<LeaderEpoch ==> StartOffset>,其中StartOffset表示当前LeaderEpoch下写入第一条消息的偏移量。
我们依旧使用之前副本A和副本B为例:
-
副本B重启了,首先它并不是像之前判断HW进行日志截断。而是,先向副本A发送OffsetForLeaderEpochRequest的请求,请求参数带上自身leaderEpoch值,副本A收到请求后判断leaderEpoch和自身leaderEpoch保持一致,然后发送自己的LEO给副本B
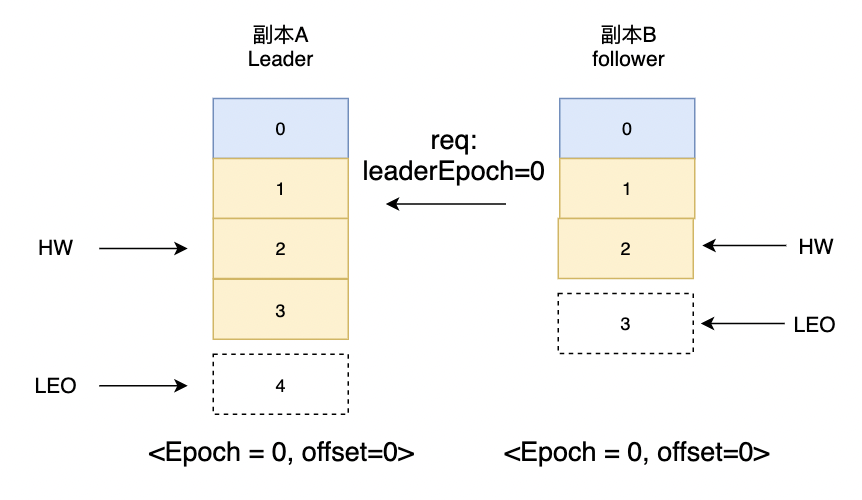
副本B收到发现LEO大于自身的LEO,所以副本B不用截断日志,之后副本B发送请求同步数据,更新自己的LEO和HW值。
-
之后副本A宕机,副本B成为新的Leader,那么对应的leaderEpoch就变成了1。副本B如果有新的消息写入或者与副本A中的LeaderEpoch不一致,需要记录矢量
<LeaderEpoch = 1, offset=3>,并返回给A也就是副本A对应的LEO。副本A判断自身的LEO小于返回的LEO,进行数据截取操作。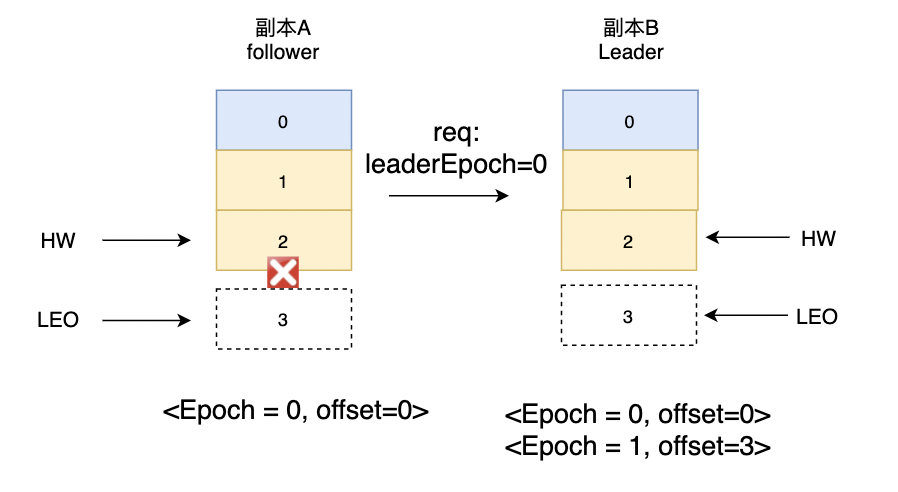
小结
kafka通过多副本机制,满足了集群的可靠性,所有数据的读写只能通过Leader副本,通过ISR集合与HW、LEO机制来控制客户端可读取的数据。follower副本需要同leader副本同步拉取数据来保持数据的一致性,每次数据请求会更新自己的HW和LEO值以及leader副本的HW值。为了保证同步不出现丢数据或者不一致的情况,kafka又采用了leader epoch机制,每次出现副本切换时都会更新leaderepoch加1。当新的leader有数据写入时会在leader-epoch-checkpoint文件中进行变更。